
DeepSeek V4 landed: Imbecile, Mini Max fell, Young Waida panicked
Yin Weidar was downgraded from "necessary" to "optional" in China's big modeled moat.

DeepSeek V4 is finally online. This is a moment that has been waiting for almost five months. A flash version of the main MoE model for 1T parameters + 285B, followed by a full 1.6T version of Pro, with full open source to the GitHub, Apache 2.0 protocol, with weights and deployment codes released simultaneously。
As soon as the model came out, capital markets responded in three separate and mutually reinforcing ways。
Different responses from capital markets
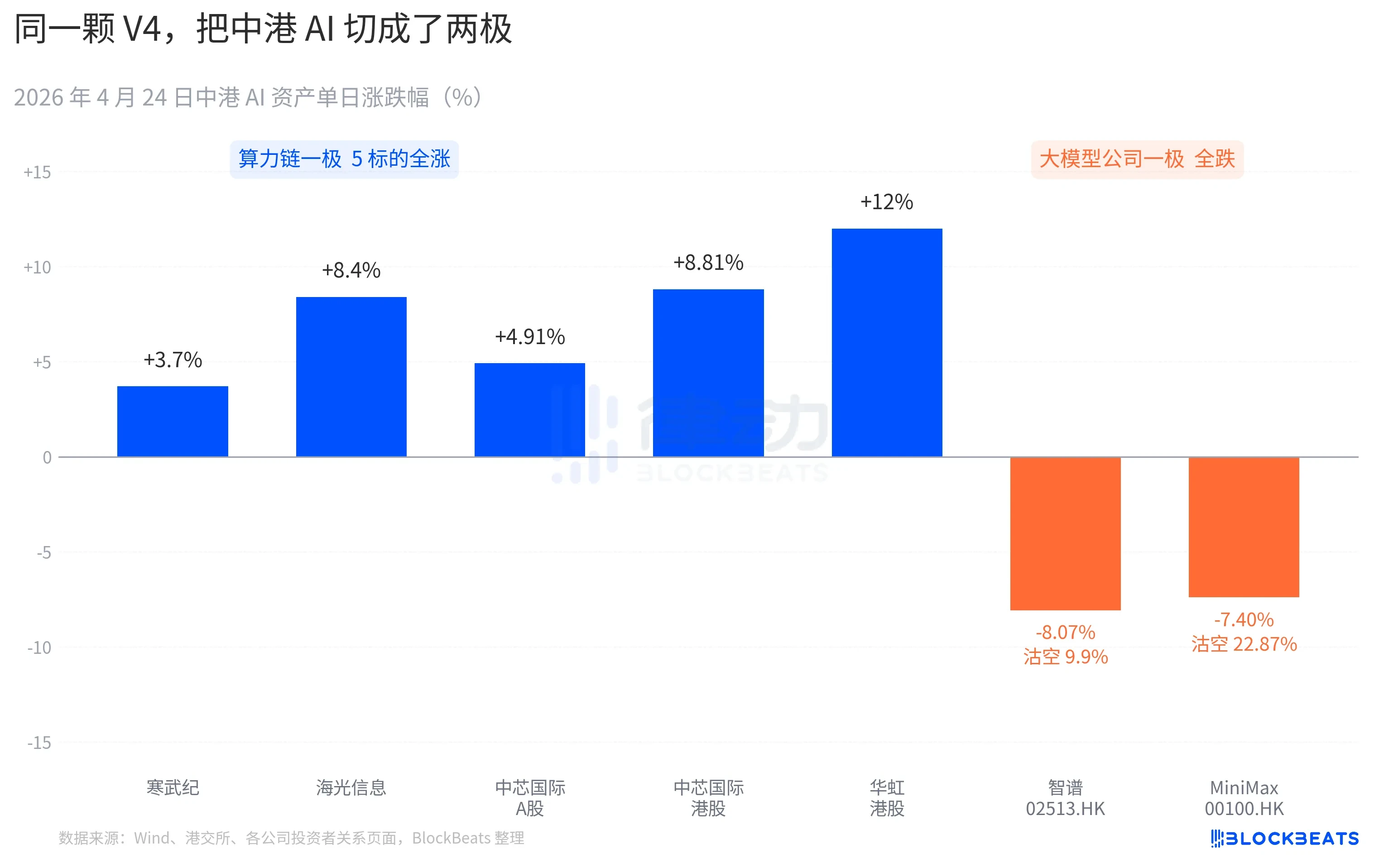
A THE HEAD OF THE STOCK-CALCULATION CHAIN IS ALMOST FULL-LINED. THE COLD MARTIAL ARTS CAME OUT OF 11 SOOYANGS, AN INCREASE OF 3.7 PER CENT A DAY, A CUMULATIVE BREAKTHROUGH OF 60 PER CENT A MONTH. TEN PERCENT OF THE SEALIGHT INFORMATION DISCS WERE TOUCHED, RISING AND CLOSING + 8.4 PERCENT. +4.91 PER CENT FOR CHINA-CHARLIE-A AND +8.81 PER CENT FOR PORT UNITS. THE PEAK WAS +18% AND CLOSING +12%. ETF SINGLE-DAY GOLD, $2.4 BILLION, SIZE STATION HIGH。
This is another color at the head of Port Stock Model. The intelligence index (02513.HK) fell by 8.07 per cent, with a drop rate of 9.9 per cent. Mini Max (00100.HK) fell by 7.40 per cent, and the emptiness rate surged to 22.87 per cent. The latter is the highest single-day empty data of the AI plate in the last three months. The core competitiveness of these two companies, both represented by the Hong Kong shares AI market in the second half of 2025, was written in the IPO book as the same phrase, "the large self-study base model"。
The response from the other side of the Pacific is equally specific. Young Waida dropped 1.8 per cent last night, and one time it fell to -2.6 per cent, flatting the whole day. A market review of Bloomberg compared the drive to the V3 DeepSeek Time on January 27th. The difference is, in January, it was a panic sale, evaporating 60 billion dollars a day. This time it's more like a recalculation, a moderate measure but clear direction. There is a new expression in the minutes of the buyer's agency's research that “China's AI reasoning needs are beginning to be delinked from North America's AI reasoning needs”。
THIS IS THE FIRST JUDGEMENT THAT WAS WRITTEN BY THE MARKET IN 24 HOURS AFTER V4 LANDED. WHEN THE OPEN SOURCE WINS, THE MONEY BEGINS TO BE RE-SELECTED, AND WHAT CAN BE PRICED IS NOT THE MODEL ITSELF, BUT THE CARD ON WHICH IT RUNS AND THE CHAIN OF INDUSTRY。
30 DAYS, 11 NEW MODELS, V4
THE TIME WINDOW FOR THE RELEASE OF V4 IS ITSELF PART OF THE REASON FOR THE MAGNIFICATION OF THE REACTION。
Pull the camera over 30 days. Between 26 March and 24 April, at least 11 large models with significant impact were released or significantly updated globally, with the list covering almost all major players. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Dark side of the Moon Kimi K2.6, Ali Qwen3-Next, 2.5 Pro, Quetzette 3.0 and Kimi K2.6 Plus, last released early on 23 April, DeepSeek V4。
On average, every 2.7 days a new model comes out. It's too late for even the fund manager to read the release. But by going through this 30-day IA asset K line, there's only one name that can keep track of it. April 8th GPT-5.5 led to a single-day increase of 4.2 per cent in the city and peaked in one day. Next is DeepSeek V4, April 23-24, driving the Chinaport Calculator Chain out of continuous jumps。
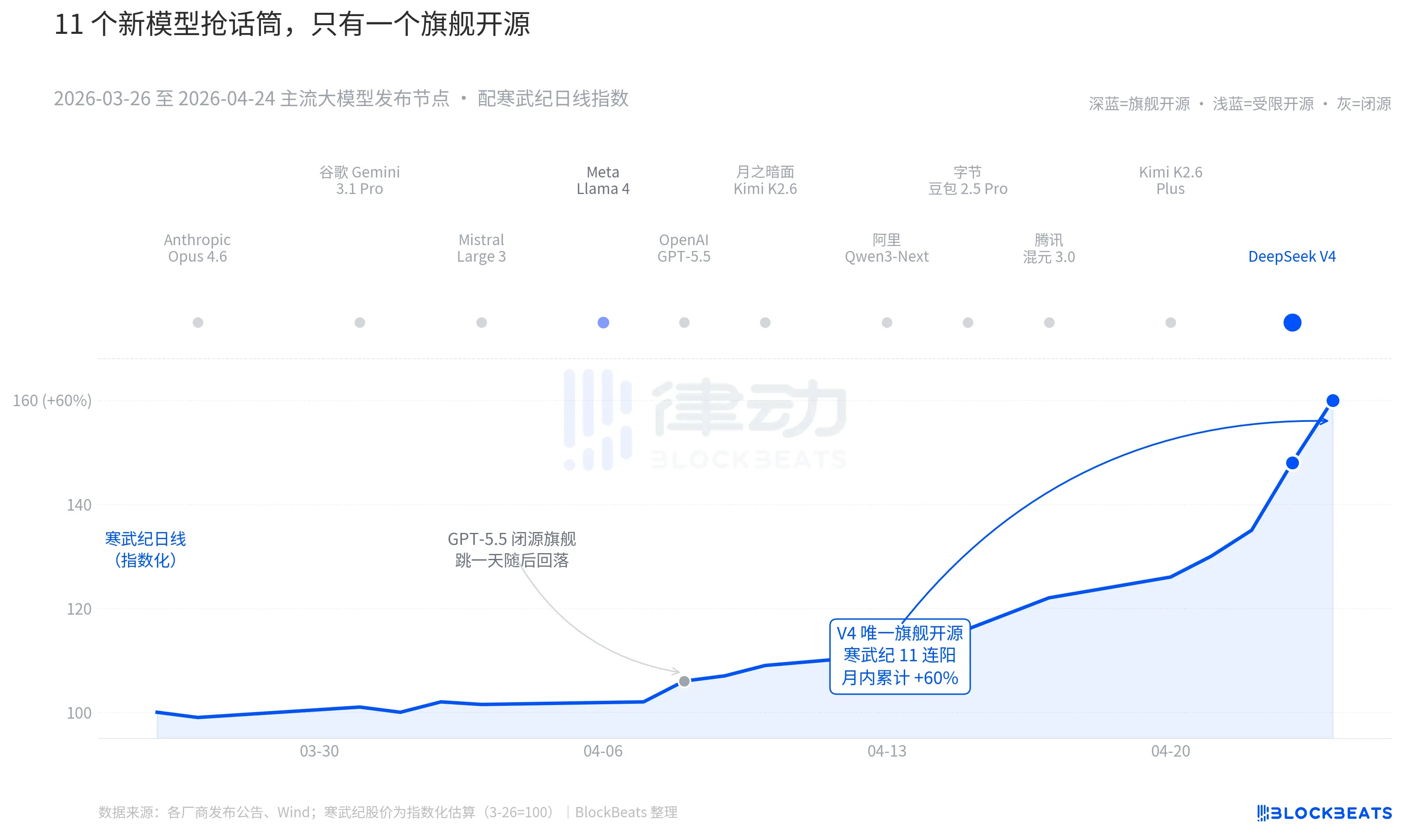
The difference is not in the model capacity itself. The difference between these 11 models on the LMArena ranking list, in most cases not exceeding 50 points, is in the narrow band of the "same slot". The difference between two things。
The first is open source. Of the first 10 models, only Llama 4 is open, but the Llama 4 weight agreement is accompanied by a long list of commercial restrictions, the European and American community of developers evaluates cold, and OpenRouter falls the top ten on the third day of the line. The V4 agreement is Apache 2.0, with no threshold for weights, unlimited commerciality and simultaneous release of reasoning codes. This was the first flag open source model in the last six months to allow closed source camps to be under pressure at the same time in performance, price, and three dimensions of openness。
The second is timing. In the context of the successive amplification of closed-source camps, open-source narratives are being squeezed repeatedly. Opus 4.6 pushed the code task SWE-Bench to a new height, GPT-5.5 set the price per million token at the down anchor point of $1.25. The debate over whether the open source could catch up with it has been going on in Silicon Valley for two years. V4 pushed the argument to the 9 million open source flagship with a one-month living estimate。
ACCORDING TO A LARGE DOMESTIC FUND MANAGER IN A ROAD SHOW, "V4 LEFT A DISCOUNT ON THE OPEN SOURCE MODEL VALUATION, AND V4 BEGAN TO COLLECT BACK."
DeepSeek changed the price sheet for the algorithm supply chain
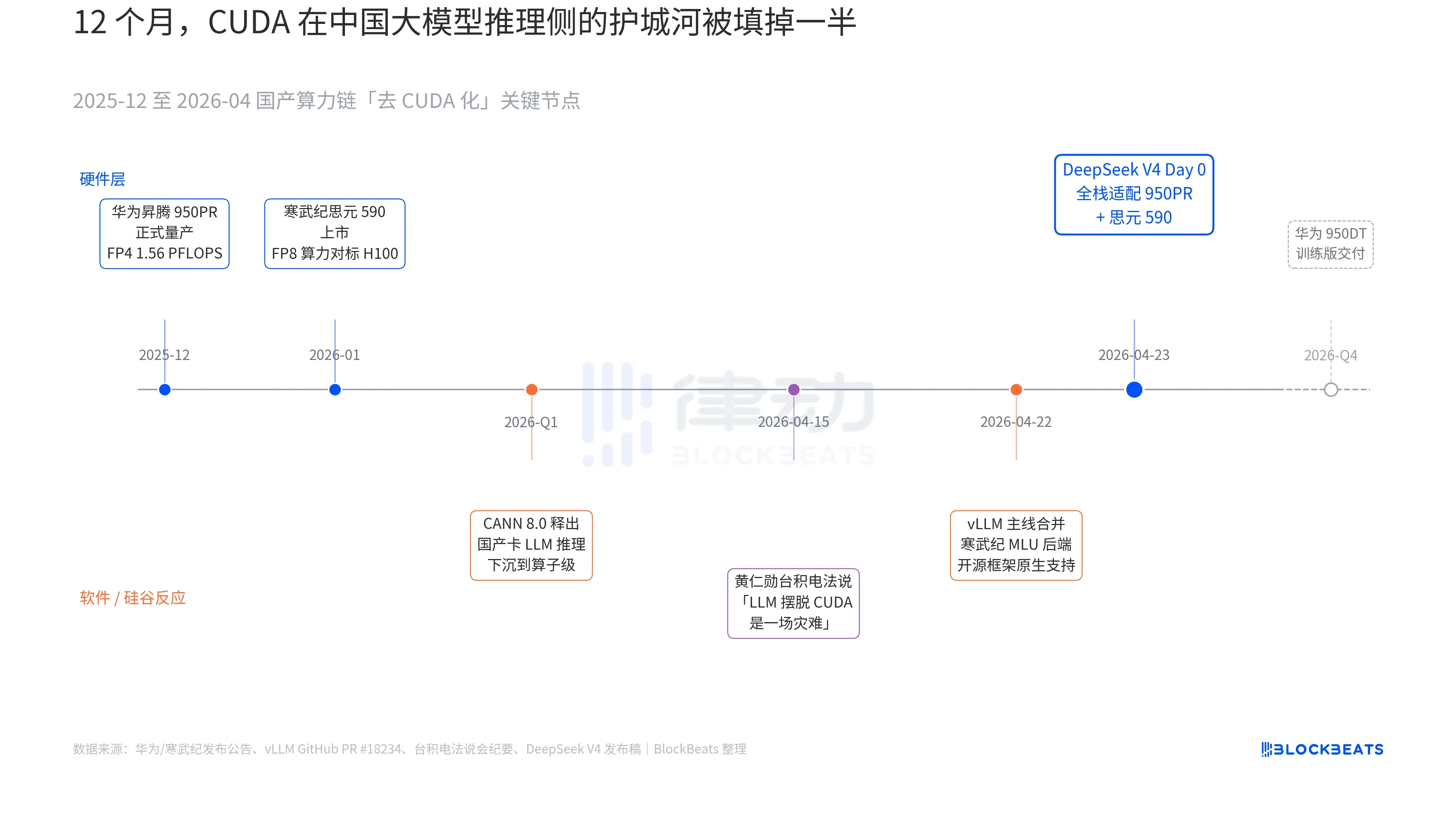
A line in the V4 release never appeared before in the official files of any large Chinese model: "Day 0, the whole house fit for the cold martial arts, 590 and China to placate 950PR, the deployment code is synchronized with the open source. In the past 12 months, three parallel dark lines have been drawn together in order to understand the magnitude of this line. These three dark lines are the reaction of hardware, software and Silicon Valley, respectively。
The first dark line is on the side of the chip. China’s 950PR, official production in December 2025, FP4 calculus 1.56 PFLOPS, HBM capacity 112GB, is the first time that the national production AI chip has matched the British Wida B series on hard indicators. In the MoE reasoning task of the V4 1T parameter, single-calories are 2.87 times higher than H20. Accompanying CANN 8.0 software stacks, sunk the LLM reasoning framework optimization down to the algorithm level, and DeepSeek's public Benchmark shows that the end-to-end reasoning on V4 is delayed by 35% below the H100 cluster of the same size at the dot (8 card,950PR). The 590 data of the Cold Wu Genius are more radical, with a single chip FP8 calculator H100 at less than half the price。
The second dark line is on the software side. The vLM main line merged the MLU backend PR on April 22, and the open source reasoning framework was first-born in support of non-British GPU. The CDU of Sealight Information takes another route through ROCm, but it runs the entire MoE route layer of V4. This means that the deployment of V4 is no longer "can only run on one national card" but "can choose between multiple national cards". The ecological dependence on single-point suppliers has been broken, and this is the key point of intervention。
The third dark line comes from Silicon Valley. On April 15, Huang In-hoon was asked by analysts at the conference about the progress of China's national production, which was so cold and concrete that "if they could really get LLM out of CUDA, it would be a disaster for us." Nine days later, DeepSeek gave the answer with a line of Day 0 announcements。
the term "national production substitution" has been used in the last three years to make no sense. however, after the morning of 24 april, for the first time, the matter had specific data that could be priced by the capital market. single-calories, late end-to-end reasoning, reasoning costs, commercial deployable codes have quietly pushed this long rhetorical war to the threshold of prevention。
Cold Wu stock price 11 The logic of Nyang is hidden here. It is no longer a "national GPU concept unit" but a "DeepSeek V4 reasoning infrastructure provider". The same logic explains the 12 per cent increase in the Waoxin Port stock, which is a 950PR 7nm equivalent process. Each of the V4 tokens, which runs on the domestic production, means that the capacity that would otherwise have flowed to Inweida and the telecommunications reservoir was partially intercepted in the Pearl River Delta。
AND THE NEXT STEP IS READY. AS PART OF THE ROAD MAP, 950DT (TRAINING VERSION) WAS SCHEDULED TO BE DELIVERED IN THE FOURTH QUARTER OF 2026, WITH THE CORRESPONDING TARGET BEING "V5 OR EQUIVALENT MODEL TRAINING IN THE 10,000-CALORIE CLUSTER " . IF THIS ROAD RUNS, CUDA WILL BE DOWNGRADED FROM "NECESSARY" TO "OPTIONAL" IN THE MOAT ON THE SIDE OF CHINA'S BIG MODEL TRAINING。
