
a16z: AI를 위한 Amnesia는, “cure” 그것을 지속적인 학습할 수 있습니까
Breakthrough는 배포 및 훈련 될 때 모델을 강력하게 만드는 것입니다. 압축, 요약, 학습。

본래 제목: 왜 우리는 정기적인 Learing를 필요로 합니다
Malika Aubakirova, Matt Bornstein, a16z 암호화
원래 언어: Deep tide TechFlow
Christopher Nolan의 Memento에서 최고의 배우인 Leonard Shelby는 부서진 순간에 살고 있습니다. 뇌 손상은 새로운 기억의 번식과 손실에서 고통을 일으키는 원인이되었습니다. 몇 분마다, 그의 세계는 재설정, 영원한 "이 순간에"에 갇혀 - 그냥 무슨 일이 일어나고 무슨 일이 일어나는지 기억. 생존하기 위해 그는 두뇌가 수행 할 수없는 메모리 기능을 대체하기 위해 몸을 쓰고 촬영했습니다。
큰 언어 모델은 비슷한 영원한 시간에 살고있다. 훈련 후, 지식의 질량은 매개 변수에 동결되고 모델은 새로운 기억을 만들고 새로운 경험의 빛에 매개 변수를 업데이트하지 않습니다. 이 간격을 채우기 위해, 우리는 비계에 뒀습니다: 짧은 기간 handprint로 채팅 역사, 외부 노트북으로 retrieval 체계, 문신으로 체계 hints. 그러나 모델 자체는 정말이 새로운 정보를 내부화하지 않았습니다。
연구원의 성장 수는 충분하다고 생각합니다. CONTEXT LEARNING (ICL)은 대답 (또는 응답의 파편)이 이미 세계의 일부에 존재하면 문제를 해결합니다. 그러나 모델이 새로운 지식과 경험을 직접 포함하는 방법이 필요한 이유가 좋은 이유가 있습니다. 배포 후, 실제로 발견해야 할 문제 (예 : 새로운 수학 인증서), CONFRONTATIONAL 시나리오 (예 : 보안 주의), 또는 언어에서 표현하는 너무 미묘한 지식。
context 학습은 임시입니다. 실제 학습은 압축을 필요로 합니다. 우리가 모델을 계속 압축 할 수 있기까지, 그것은 기억 debris의 영원한 순간에 갇혀있을 수 있습니다. 우리가 자신의 기억 구조를 배우기 위하여 모형을 훈련할 수 있는 경우에, 외부 주문을 받아서 만들어진 공구에 relying 보다는 오히려, 우리는 완전히 새로운 스케일링 차원을 자물쇠로 열 수 있습니다。
이 필드는 호출지속적인 학습(연속 학습) 이 개념은 새로운 것은 아닙니다 (McCloskey와 Cohen 1989 종이를 보십시오), 그러나 우리는 현재 AI 분야에 있는 가장 중요한 연구 방향의 한을 고려합니다. 과거 2 ~ 3 년 동안 모델링 용량의 폭발적인 성장은 알려진 모델과 점점 더 분명한 차이를 만들었습니다. 이 문서의 목적은 우리가 필드의 최고 연구원에서 배운 것을 공유하는 것입니다, 지속적인 학습의 다른 경로를 명확하게하고 기업가 생태의이 주제의 개발에 기여하는 데 도움이。
참고 : 이 기사의 모양은 지속적인 학습 영역에서 자신의 작업과 통찰력을 공유하는 우수한 연구원, 의사 학생 및 기업가의 그룹과 집중 교환에서 혜택을받습니다. 이론적인 기초에서 공학 현실의 포스트 배치 학습, 그들의 통찰력은 우리가 혼자 쓴 것보다 더 견고한 기사를 만들었습니다. 당신의 시간과 생각을 주셔서 감사합니다
context로 시작합시다
Parameter-level 학습을 방어하기 전에 (즉, 모델 무게를 업데이트하는 학습), context 학습이 작동한다는 사실을 인정하는 것이 필요합니다. 그리고 계속 승리 할 강한 인수가있다。
변압기의 본질은 순서의 상태에 근거를 둔 다음 토큰 예측기입니다. 올바른 순서로, 당신은 놀라운 풍부한 행동을 얻을, 당신은 무게를 만질 필요가 없습니다. 왜 컨텍스트 관리, 팁, 지침 미세 조정 및 몇 가지 샘플 예제가 너무 강력합니다. Smart encapsulation은 정적 매개 변수이며, 창에 먹이로 극적으로 변경할 수 있습니다。
자율 프로그래밍 스마트 스케일링에 대한 커서의 최근 심층적 기사는 좋은 예입니다. 모델 무게는 고정되어 있으며, 시스템이 실행되는 것은 컨텍스트의 정밀한 레이아웃입니다. 요약 할 때, 자율 작업의 몇 시간 동안 일관성을 유지하는 방법。
OpenClaw는 또 다른 좋은 예입니다. 특수 모델 특권 (하단에 모두 사용할 수 있음) 때문에 폭발하지는 않지만, 큰 효율성을 가진 작업 조건으로 컨텍스트 및 도구를 변환하기 때문에 : 당신이해야 할 것을 추적하고, 중간을 파괴하고, 이전 작업의 마지막 기억을 유지 할 때 결정. OpenClaw는 독립적 인 분야에 지능의 "쉘 디자인"을 제기했습니다。
프로젝트가 처음 등장했을 때, 많은 연구원들은 "advertisements alone"가 적절한 인터페이스가 될 수 있다는 사실에 대해 좌절했다. 잭처럼 보입니다. 그러나, 그것은 변압기 건축의 본래 제품입니다, retraining 요구하지 않으며 모형 진도로 자동적으로 격상됩니다. 모델은 더 강한, 힌트는 더 강한. "simplistic but primitive" 인터페이스는 종종 아래 시스템에 직접 연결하기 때문에 승리합니다. 지금까지, LLM의 trajectory는 정확히 그것입니다。
국가 공간 모델: context의 스테로이드 버전
컨텍스트 학습 모델은 원래 LLM에서 지능형 순환으로 이동하는 주류 워크플로우로 압력을 증가시킵니다. 과거에, 그것은 완전히 채워지기 위하여 문맥 창을 위해 상대적으로 드물었습니다. 일반적으로 LLM이 다양한 작업의 긴 라인을 수행하도록 요청할 때 발생합니다. 애플리케이션 레이어는 더 직접적인 방식으로 채팅 기록을 절단하고 압축 할 수 있습니다。
그러나 지능적인 몸에 대한 임무는 항상 사용할 수있는 상황에 큰 부분을 먹을 수 있습니다. 지능형 사이클의 각 단계는 첫 번째 순서가 전달되는 상황에 따라 달라집니다. 그리고 그들은 종종 20에서 100 단계 나중에 실패, 라인이 깨지기 때문에 : 상황은 채우기 때문에, 일관성은 분해되고, 포함 할 수 없습니다。
그 결과, 주요 AI 실험실은 이제 중요한 자원 (즉 대규모 교육 작업)을 열애하여 초경량 창에 대한 모델을 개발합니다. 이것은 이미 효과적인 방법을 기반으로 한 자연 경로입니다 (맥주에서 재배) 그리고 산업 's 일반적인 추세와 함께 라인에있다. 가장 일반적인 구조는 고정 된 메모리 층, 즉, 국가 공간 모델 (SSM) 및 선형주의 변형 (이하 SSM으로 간주), 일반주의 사이에서 삽입. SSM은 context의 근본적으로 더 나은 스케일링 곡선을 제공합니다。
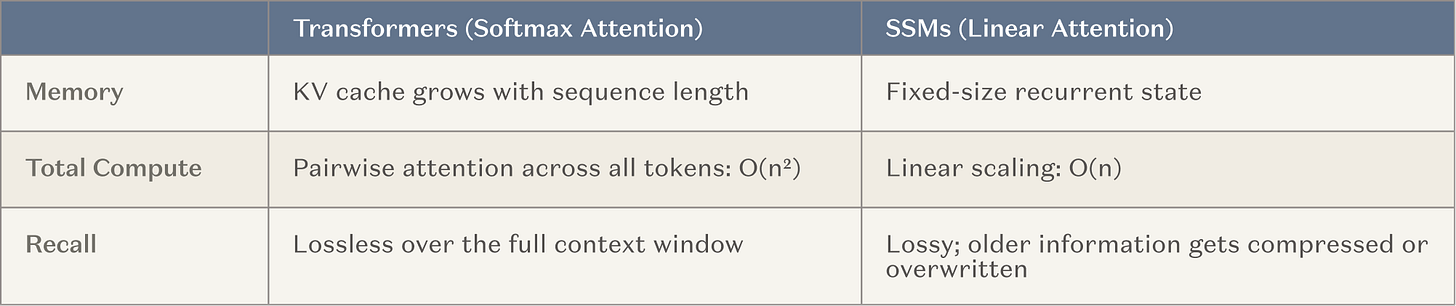
그림: 전통적인 주의 기계장치의 사기에 비교된 SSM
이 목표는 기존의 변압기에 의해 제공 된 광범위한 기술과 지식을 잃지 않고 20 ~ 약 20,000에서 여러 주문까지 일관된 단계의 수를 높이는 지능을 돕는 것입니다. 성공적인 경우, 이것은 긴 실행 지능을 위한 중요한 돌파구입니다。
당신은 연속 학습의 형태로 볼 수 있습니다 : 모델 무게가 업데이트되지 않았지만 외부 메모리 층은 단단히 교체가 필요하다는 것을 도입했습니다。
그래서이 비 모수 방법은 실제적이고 강력합니다. 지속적인 학습의 모든 평가는 여기에서 시작됩니다. 질문은 오늘날의 컨텍스트 시스템 작동 여부는 아니지만, 그것은 아닙니다. 질문은: 우리는 천장을 본 가지고 있고, 새로운 접근은 저희를 더 지도할 수 있습니까。
context에 누락 된 것은 무엇입니까
"AGI와 사전 훈련 된 것들은, 감각에서, 그들은 압도적 인 ... 인간은 AGI가 아닙니다. 예, 인간은 기술 기반을 가지고 있지만, 그들은 지식의 큰 거래를 부족합니다. 우리는 지속적인 학습에 의존합니다。
슈퍼 스마트 15 세 소년을 만드는 경우, 그는 아무것도 모른다. 좋은 학생, eager 배울. 당신은 말할 수 있습니다, 프로그래머가, 의사가 간다. 배포 자체는 학습, 테스트 및 오류의 일부 종류가 포함되어 있습니다. 완제품을 끊지 않는 과정입니다. 일리아 Sutskever
무제한 저장 공간을 가진 체계를 상상하십시오. 세계에서 가장 큰 서류의 각각은 잘 색인되고 접근할 수 있습니다. 아무것도 찾을 수 있습니다. 그것은 배울
아무것도. 압축을 할 필요가 없습니다。
이것은 Ilya Sutskever: LLM은 근본적으로 압축 알고리즘입니다. 훈련 과정에서, 그들은 매개 변수로 인터넷을 압축합니다. 압축은 손상이고, 그것에게 강한 손상의 종류입니다. 압축력 모델은 구조, 일반화 및 구성 표지판을 찾습니다. 모든 훈련의 하드 백업 샘플의 모델은 하단 패턴의 모델이 아닙니다. 압축은 스스로 학습한다。
철적으로, 훈련 중에 LLM을 허용하는 메커니즘 (소형 데이터 압축, 전송 가능한 표시로 압축)은 우리가 배포 후 계속 하도록 거부하는 것을 정확하게했다. 우리는 그 순간에 압축을 멈추고 외부 메모리로 교체했습니다。
물론 대부분의 스마트 바디 케이싱은 몇 가지 방법으로 컨텍스트를 압축합니다. 그러나 모델 자체가 압축, 직접 및 큰 규모에서 배울 수 있어야하는 쓴 교훈은 아니지만
Yu Sun은이 토론의 예를 공유합니다 : 수학. Fermat theorem에서 보기. 몇 년 동안 mathematician은 올바른 문학이 부족하기 때문에 그것을 증명했지만 솔루션이 매우 소설이기 때문입니다. 수학과 마지막 대답의 지식 사이에 너무 많은 개념적인 거리가 있습니다。
Andrew Wiles, 그는 마침내 1990 년대에 일어났을 때, 고립에서 일하는 7 년을 보냈다, 대답에 도달하는 새로운 기술을 발명했다. 그의 증명서는 2개의 다른 수학 분지에 성공적인 교량에 의존합니다: 타원형 곡선 및 모형 모양. Ken Ribet은 이전에이 연결이 Fermatian Theorem을 자동으로 해결 할 수 있다는 것을 증명했지만, 아무도 Wiles 전에 브리지를 구축하기 위해 이론적 도구가 없습니다. Grigori Perelman은 Pongarai의 추측의 증거와 동일한 일을 할 수 있습니다。
핵심 문제는:이 예는 LLM이 뭔가 부족한 증거, 우선 업데이트 할 수있는 몇 가지 능력과 정말 창의적으로 생각? 또는 이야기는 단지 반대를 증명합니다 -- 모든 인간 지식은 훈련되고 재구성될 수 있는 자료, 와글 및 퍼엘만, 그러나 LLM가 더 큰 가늠자에 할 수 있는 무슨을 보여주습니까
질문은 적법하고 대답은 불확실합니다. 그러나 우리는 아래 학습의 많은 범주가 오늘 실패하고 매개 변수 레벨 학습이 유용 할 수 있다는 것을 알고 있습니다. 예를 들면:

그림: Context 학습 실패, 매개변수 학습을 위한 가능한 문제 범주
UXPA(사용자경험전문가협회)는 제품 및 서비스 UX를 리서치, 디자인, 평가하는 인력을 지원한다. 몇몇 모형은 너무 높, 너무 보이지 않는, 너무 구조상으로 깊은. 예를 들어, 의료 검사에서, 종양의 시각 질감에서 virtuous pseudo-tumour를 구별하는 시각적 질감, 또는 말하는 사람의 독특한 리듬을 정의하는 오디오의 약간 변동, 쉽게 정확한 어휘로 끊지 않습니다。
언어는 그들과 유사할 수 있습니다. 더 이상 힌트는이 일을 운반 할 수 없습니다. 그러한 지식은 체중 내에서만 살아남을 수 있습니다. 그들은 학습 표지판의 공간에서 살고, 단어가 아닙니다. 컨텍스트 창의 성장에 관계없이 텍스트에 설명 할 수없는 항상 지식이 있고 매개 변수에 의해 수행 할 수 있습니다。
이것은 명백한 "로봇이 당신을 기억한다는 것을 설명 할 수 있습니다"기능 (ChatGPT의 메모리와 같은) 종종 사용자가 놀라지 않고 불편하게 만듭니다. 사용자가 "remember"하지만 "power"를 원하지 않습니다. 당신의 행동 패턴을 내부화 한 모델은 새로운 장면에 맞출 수 있습니다; 단순히 역사가 할 수없는 모델. "이것은 당신이이 전자 메일에 대답하는 마지막 시간을 썼는 것입니다"(동사)과 "나는 당신이 필요로하는 것을 예측하기 위해 충분히 생각의 방법을 이해했습니다"검색과 학습의 간격입니다。
지속적인 학습
지속적인 학습에 많은 경로가 있습니다. 디바이딩 라인은 " 메모리 없음"이지만:압축이 발생했을 때이 경로는 uncompressed (순수 검색, 무게 동결)에서 전체 내부 압축 (무게 학습, 모델이 더 스마트)에 이르기까지 스펙트럼을 따라 배포됩니다. 중요한 영역 (모듈)。
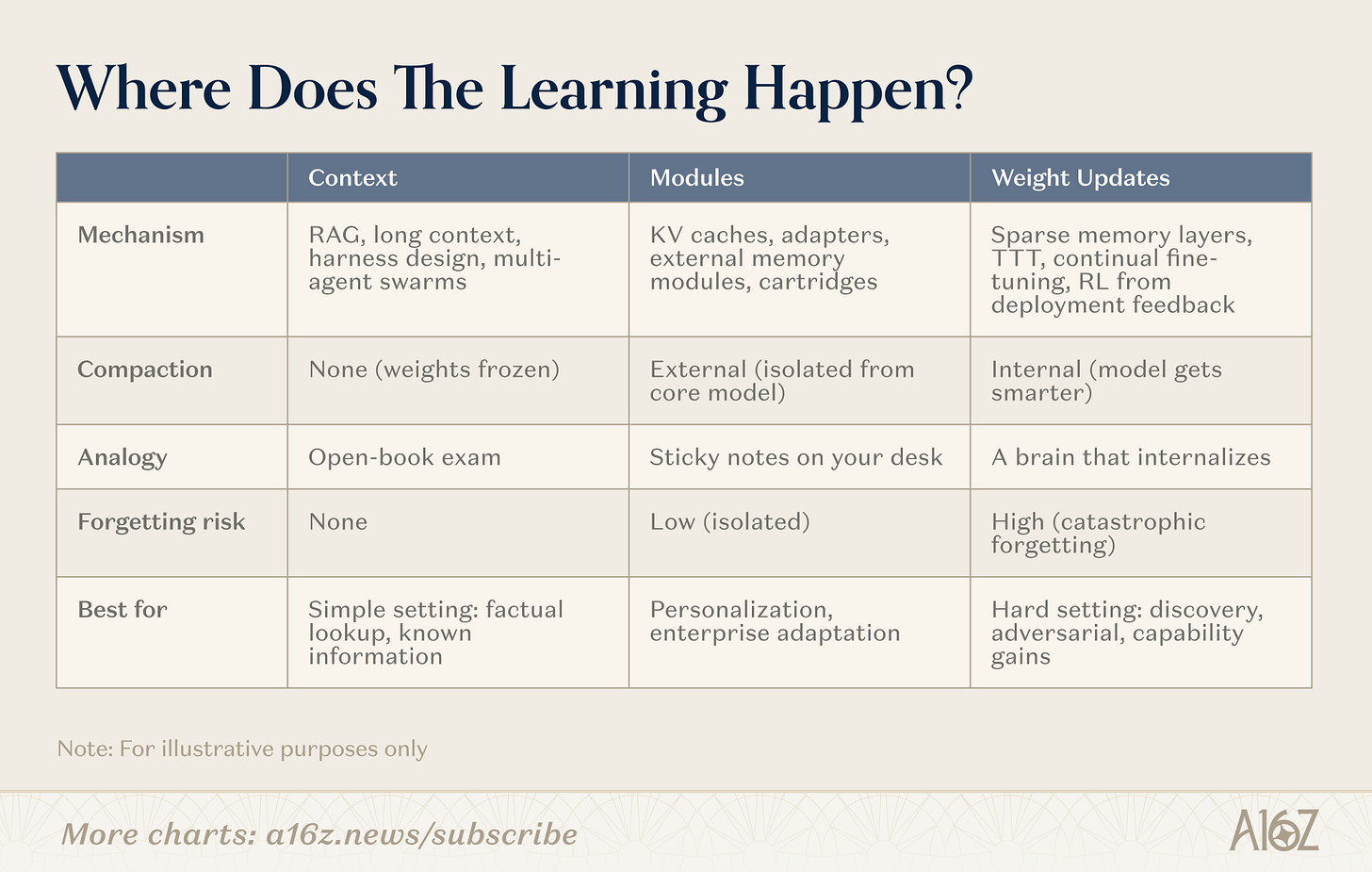
그림: 연속 학습을위한 3 개의 통로 - 컨텍스트, 모듈, 무게
설정하기
컨텍스트의 끝에, 팀은 더 지능형 검색 튜브, 스마트 바디 케이스 및 힌트 조직을 구축합니다. 이것은 가장 성숙한 범주입니다: 인프라는 검증되고 배포 경로는 명확합니다. 한계는 깊이입니다: 문맥의 길이。
주목할만한 새로운 방향: Multi-Intellectual Structures는 컨텍스트 자체에 대한 스케일링 전략입니다. 단일 모델이 128K 토큰 창에 confined되면 지능형 바디의 좌표 세트 - 자체 컨텍스트로 각, 문제에 초점을 맞춘 단일 조각, 그리고 다른 통신의 결과 - 전체 무한한 작업 메모리를 대략적으로 할 수 있습니다. 각 스마트 바디는 자체 창에서 컨텍스트 학습을 합니다; 시스템 집계. Karpathy의 가장 최근의 사례 연구 프로젝트와 Cursor의 웹 브라우저는 초기 사례입니다. 이것은 순수하게 비 모수 접근 (무게를 바꾸지 않기 위하여), 그러나 그것은 두드러지게 상황 체계가 달성할 수 있는 천장을 올리。
모듈
모듈 공간에서, 팀은 임베디드 지식 모듈 (압축 KV 캐시, 어댑터 레이어, 외부 메모리 저장)을 구축하여 변형없이 일반적인 모델을 전문으로합니다. 적절한 모듈을 가진 8B 모델은 대상 작업에 109B 모델의 성능을 일치 할 수 있으며 메모리 용량은 분수 만 일치합니다. 이 매력은 기존의 변압기 인프라와 호환됩니다。
무게
체중 업데이트의 끝에서, 연구원은 진정한 매개 변수 레벨 학습을 추구: 관련된 매개 변수 세그먼트의 얇은 메모리 레이어만 업데이트, 피드백에서 모델의 향상된 학습 사이클을 최적화, 그리고 이유의 상황에 압축 무게의 테스트에 훈련. 이것은 가장 깊고 가장 어려운 배포이지만, 모델을 완전히 새로운 정보 또는 기술을 내부화 할 수 있습니다。
모수를 새롭게 하기를 위한 많은 특정한 기계장치가 있습니다. 몇몇 연구 방향은 주어집니다:
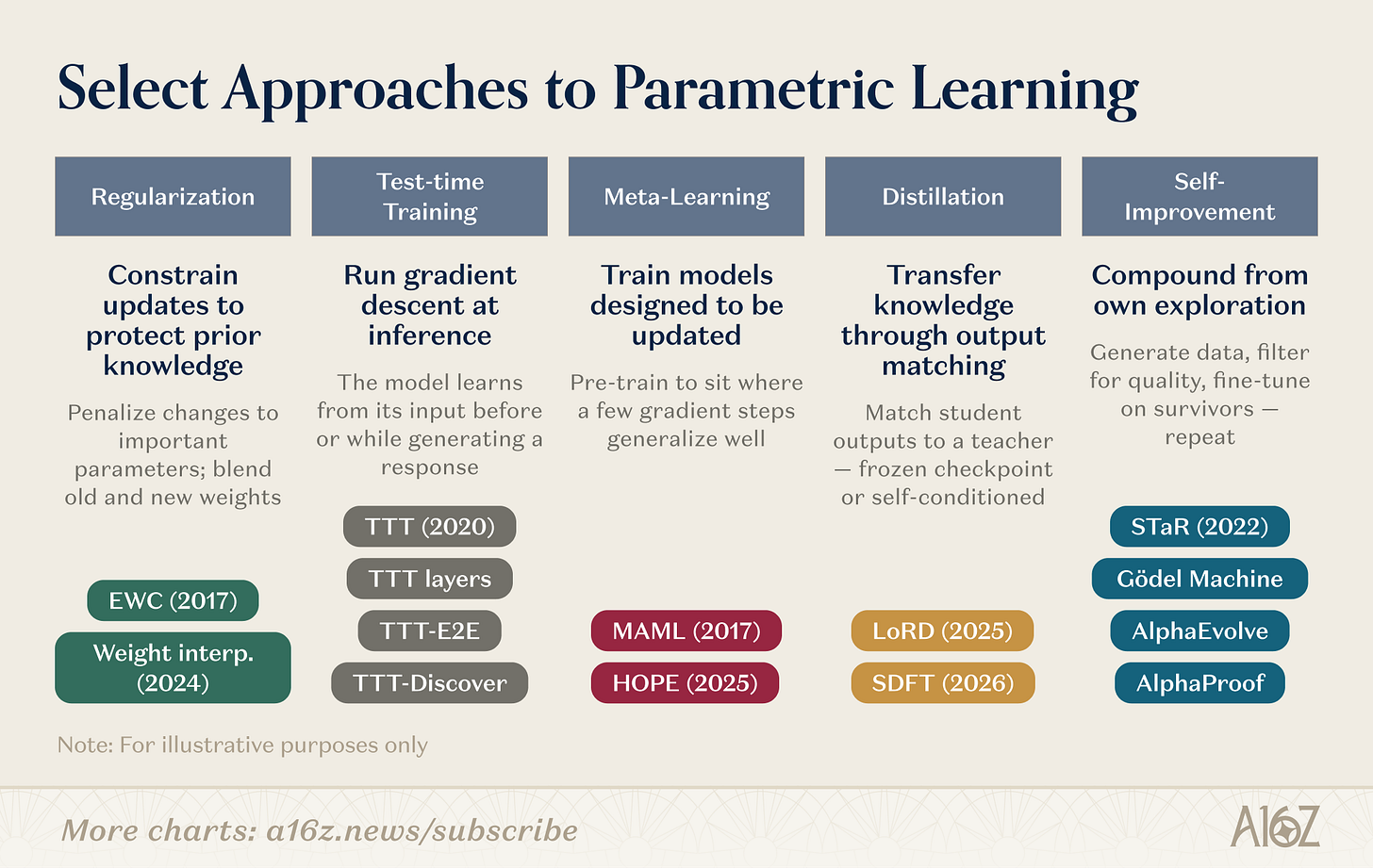
그림 : 체중 학습을위한 연구 방향 개요
무게를 다는 학문은 몇몇 평행한 노선을 덮었습니다。일정화 및 무게 공간 접근가장 오래된: EWC (Kirkpatrick 외., 2017)는 이전 작업에 매개 변수의 중요성에 따라 매개 변수 변경을 처벌; 무게 인터랙션 (Kozal et al., 2024)는 매개 변수 공간에서 오래된 새로운 무게 구성을 혼합하지만, 큰 규모에 취약합니다。
시험 중 훈련Sun et al. (2020)에 의해 만들어진, 나중에 건축 (TTT 층, TTT-E2E, TTT-Discover)의 원래 언어로 개발, 아이디어는 다릅니다 : 테스트 데이터에 그리스를 만들고 필요한 순간에 매개 변수로 새로운 정보를 압축하기 위해。
Yuan 학습질문은: 우리는 학습하는 방법을 배우기 위하여 모형을 훈련할 수 있습니까? MAML (Finn et al., 2017)의 몇 가지 샘플 친화적 인 매개 변수의 초기화에서 Behrouz et al. (Nested Learning, 2025)의 임베디드 학습으로 모델을 레이어 최적화 문제로 구조화하고, 빠르게 적응하고 생물학적 기억의 통합에 영감을 얻은 다른 시간 규모에서 느린 업 모듈을 실행。
관련 제품이전 작업의 지식은 언 교사 검문소와 일치하는 학생 모델에 의해 유지됩니다. LoRD (Liu et al., 2025)는 모델을 절단하고 버퍼 영역을 동시에 재생하여 유지할 수있는 지점으로 효율적으로 운영 할 수 있습니다. Self-distillation (SDFT, Shenfeld et al., 2026)는 테스트 신호로 전문가 조건에서 모델 's 자신의 출력을 사용하여 소스를 붓고 시퀀스의 미세 조정의 분산 메모리를 우회합니다。
반복적인 자기 개선STAR (Zelikman et al., 2022)는 소원의 자체 생성 된 체인에서 주장하는 가이드입니다. AlphaEvolve (DeepMind, 2025)는 수십 년 동안 개선되지 않은 알고리즘 최적화를 발견합니다. 은과 Sutton 's "경험의era" (2025)은 결코 멈추지 않는 경험의 지속적인 흐름으로 지능 몸의 학습을 정의합니다。
이 연구 방향은 모임입니다. TTT-Discover는 통합 테스트 훈련 및 RL 구동 탐험을 가지고 있습니다. HOPE는 단일 구조에서 느린 학습 사이클을 구현했습니다. SDFT는 각자 개량을 위한 기본적인 가동으로 증류를 켭니다. 열 사이 경계는 흐릅니다. 지속적인 학습 시스템의 차세대는 전략을 결합 할 가능성이 있습니다 : 합성 이득을 가속화하고 자기 개선을 가속화하기 위해 정기화. 시작 업의 성장 수는이 기술 창고의 다른 수준에 베팅。
지속적인 학습 기업가 정신
스펙트럼의 비 모수 끝은 가장 잘 알려져 있습니다. 쉘 회사 (Letta, mem0 및 Subconscious) 레이어와 비계를 구축하여 컨텍스트 창의 내용을 관리합니다. 외부 저장 및 RAG 인프라 (예 : Pinecone, xmemory)는 검색 백본을 제공합니다. 데이터 존재와 도전은 오른쪽 시간에 모델 앞에 오른쪽 슬라이스를 넣어 것입니다. 컨텍스트 창 확장으로, 특히 외부 원유에서 이러한 회사의 디자인 공간, 새로운 시작의 파는 점점 복잡한 컨텍스트 전략을 관리하기 위해 신흥된다。
매개변수는 이전과 더 많은 달러입니다. 이 회사는 여기에 무게의 새로운 정보를 내부에 "위치 압축"의 일부 버전을 시도하고있다. 경로는 몇 가지 다른 베팅으로 약 분할 될 수 있습니다, 어떤 모델이 출판 된 후 학습해야。
부분 압축: 당신은 retraining 없이 배울 수 있습니다。일부 팀은 임베디드 지식 모듈 (압축 KV 캐시, 어댑터 레이어, 외부 메모리 저장)을 구축하여 핵심 무게없이 일반적인 모델을 전문으로합니다. 일반적인 인수는 의미있는 압축을 얻을 수 있다는 것입니다 (만약 retrieval), 학습이 분리되기 때문에 관리 가능한 제한 내에서 안정성 플라스틱의 균형을 유지하면서 매개 변수를 분산하지. 8B 모델은 대상 임무에서 더 큰 모델의 성능을 일치하기 위해 적합한 모듈을 동반합니다. 장점은 휴대성입니다 : 모듈은 독립적으로 교환되거나 업데이트 될 수있는 기존 변압기 구조로 연결 될 수 있으며 실험 비용은 집중 교육 비용보다 훨씬 낮습니다。
RL와 의견 주기: 신호에서 학습。다른 사람들은 포스트 배포 학습의 가장 풍부한 신호가 이미 배포 사이클 자체에 존재한다는 것을 내기 - 사용자 보정의 신호, 임무 성공 또는 실패, 실제 세계 결과에서. 핵심 아이디어는 모형이 잠재적인 훈련 신호로 각 상호 작용을 대우해야 한다는 것입니다, 다만 이유를 위한 요구. 이것은 인간이 일에서 진행하는 방법과 매우 유사합니다: 일하고, 의견 얻기, 어떤 일을 내부화. 엔지니어링 도전은 얇은, noisy 및 때때로 confrontational 피드백을 catastrophic oblivion없이 무게의 안정적인 갱신으로 번역하는 것입니다. 그러나 배포에서 진정한 배우는 모델은 아래의 시스템에서 화합물 값을 수 없습니다。
데이터에 초점: 오른쪽 신호에서 학습。관련하지만 차별화 된 베팅은 병목은 알고리즘을 학습하지는 않지만 데이터 및 주변 시스템을 훈련합니다. 이 팀은 필터링, 생성 또는 지속적인 업데이트를 구동하기 위해 정확한 데이터를 종합합니다. 고품질과 잘 구조화된 학습 신호를 가진 모형이 매우 더 작은 gradient로 의미적으로 개량될 수 있다는 것을 이 presupposes. 이것은 피드백 루프 회사와 자연 연결이지만, 업스트림 질문은 강조된다 : 모델이 학습 할 수 있는지 여부, 그들은 학습하고 어떤 정도。
새로운 건축 : 하단의 학습 역량。가장 급진적 인 베팅은 변압기 아키텍처 자체는 병목이며 지속적인 학습은 근본적으로 다른 계산 조건을 요구합니다. 시간 동적 및 내장 메모리 메커니즘의 오염이있는 구조. 여기에서 인수는 구조상입니다. 연속 학습 시스템을 원하면 하단 인프라에 학습 메커니즘을 포함해야합니다。

그림: 지속적인 학습을 위한 사업 시작
모든 주요 연구소는이 범주에서 활동하고 있습니다. 몇몇은 더 나은 컨텍스트 관리 및 사고 사슬 이유를 탐구하고, 몇몇은 외부 기억 단위 또는 잠 시간 계산 관으로 실험하고, 몇몇 보이지 않는 회사는 새로운 구조를 추구하고 있습니다. 이 지역은 그 방법이 원하지 않았고, 케이스의 빵을 주었다는 것을 볼 수 없기 때문에, 하나의 수상자가 없습니다。
왜 간단한 갱신은 실패합니까
생산 환경에서 모델 매개 변수를 업데이트하면 현재 큰 규모에 용해되지 않는 일련의 실패 모델을 트리거 할 수 있습니다。

그림: 간단한 무게 갱신의 실패한 형태
공학 문제는 잘 문서화됩니다. catastrophe oblivion은 새로운 자료에서 학습에 충분히 과민한 모형이 안정성과 plasticity의 기존적인 외관을 파괴한다는 것을 의미합니다. time decomposition는 무게의 동일한 세트가 일정한 규칙과 가변 상태에 의해 압축된다는 것을 의미하고, 그 1개의 갱신은 다른 손상할 것입니다. logical integration failed because the updating of facts were spread to its inference that changes was limited to the token sequence, not semantic concept. unlearning는 아직도 불가능합니다: de minimis 가동이 없습니다, 그래서 거짓 또는 유독한 지식을 위한 정확한 외과 제거 프로그램이 없습니다。
두 번째 범주의 문제는 덜 관심을 받았다. 현재 교육 및 배포의 분리는 단지 엔지니어링 시설이 아닙니다. 그것은 보안, 감사 및 관리의 경계입니다. 이 경계를 열고, 많은 것들은 동시에 잘못 간다. 보안 정렬은 예측할 수 없습니다. 예측할 수 없게 될 수도 있습니다。
지속적인 업데이트는 데이터 중독의 공격적인 얼굴을 창조했습니다. - 느린, 팁의 지속 주입, 그러나 그것은 무게에 살고. 지속적으로 업데이트 된 모델이 버전 제어, 회귀 테스트 또는 원오프 인증에 사용할 수없는 모바일 대상이기 때문에 감사 붕괴. 사용자가 매개 변수에 상호 작용할 때, 개인 정보 보호 위험이 증가하고 민감한 정보는 양식에 구워져서 상황에 대한 정보를 검색하는 것보다 더 어렵게 만듭니다。
이들은 공존의 문제, 근본적인 불능. 핵심 건축 문제를 해결하고 싶다면 지속적인 학습 연구 의제의 일부입니다。
메모리 파편에서 실제 메모리로
Memory Fragments의 Leonard의 tragedy는 그가 작동 할 수없는 것은 아닙니다. - 그는 모든 시나리오에서 유익하고 화려한 것입니다. 그의 tragedy 이다 그 의지 never recover. 각 경험은 외부에 머물렀다 - 촬영 된 메모, 문신, 다른 사람들의 필적. 그는 검색 할 수 있지만, 그는 새로운 지식을 압축 할 수 없습니다。
레오나드가이 자기 파괴 된 미로를 통해 걸어갈 때, 진실과 활력 사이의 선은 흐르기 시작합니다. 그의 병은 그의 기억의 단식이 아닙니다그것은 그의 의미를 재건하는 그를 강제했다그는 형사와 그의 자신의 이야기의 믿을 수없는 말러 둘 다 하자。
오늘 AI는 동일한 제약 아래 실행. 우리는 매우 강력한 RETRIEVAL 시스템을 구축했습니다 : 더 긴 컨텍스트 창, 더 지능형 케이싱, 조정 멀티 인트ELLIGENCE 클러스터, 그들은 작동. 그러나 검색은 학습할 수 없습니다. 어떤 사실을 발견 할 수있는 시스템은 구조에 대해 볼 수 없습니다. 일반화되지 않았습니다. 너무 많은 훈련은 너무 DAMAGINGLY 압축 - 전송 가능한 표현 메커니즘으로 원시 데이터를 돌려 - 우리가 배포의 순간에 꺼지는 정확히。
앞으로의 경로는 단일 돌파구가 될 가능성이 있지만, 오히려 계층화 된 시스템. Context 학습은 첫 번째 방어선이 될 것입니다: 그것은 원래, 검증 및 지속적으로 개선됩니다. 모듈 식 메커니즘은 현장에서 개인화 및 특수화의 중간 접지를 해결할 수 있습니다。
그러나 실제로 어렵다 - 발견하는 숨겨진 지식, 적응, 단어에서 표현 할 수 없습니다 - 우리는 훈련 후 매개 변수로 모델을 계속 압축 할 필요가 있습니다. 이것은 얇은 건축술, meta-learning 목표 및 self-improvement 주기에서 진도합니다. 그것은 또한 모델을 의미하는 것을 재정의해야 할 수도 있습니다 : 고정 된 무게의 세트가 아니라 메모리, 업데이트 된 알고리즘 및 자체 경험의 요약 능력을 포함하는 진화 시스템。
filing 장은 성장합니다. 그러나 더 큰 장은 아카이브 장입니다. Breakthrough는 배포 및 훈련 될 때 모델을 강력하게 만드는 것입니다. 압축, 요약, 학습. 우리는 기억 손실 모형에서 경험의 빛으로 모형에 도는 점에 서 있습니다. 그렇지 않으면, 우리는 우리의 기억 Debris에 붙어있을 것입니다。
원본 링크
