
Con đường đến 10 nghìn tỷ đô la của DeepSeek: Sử dụng nguồn mở để tận dụng hệ sinh thái phần cứng nghìn tỷ đô la
Bằng cách hạ thấp ngưỡng đào tạo và suy luận, nhiều nhà sản xuất bộ nhớ, chip và mạng trong nước sẽ được đưa vào cạnh tranh cơ sở hạ tầng AI.

Tên gốc: Đại chiến lược trị giá 10 nghìn tỷ USD của DeepSeek
Tác giả gốc: @bookwormengr
Bản tổng hợp gốc: Peggy, BlockBeats
Lưu ý của người biên tập: Trong năm qua, hầu hết các cuộc thảo luận xung quanh DeepSeek đều tập trung vào hiệu suất mô hình, chiến lược nguồn mở và cuộc chiến giá cả. Nhưng nếu bạn chỉ hiểu DeepSeek từ góc độ "liệu nó có bán đăng ký hay không", "liệu nó có đa phương thức hay không" và "liệu nó có thể là tác nhân mã hóa hay không" thì có thể nó đã đánh giá thấp những gì nó thực sự muốn thay đổi.
Bài viết này đưa ra một nhận định cấp tiến hơn: Mục tiêu của DeepSeek không nhất thiết là kiếm tiền thông qua lớp ứng dụng trong thời gian ngắn mà là định hình lại cấu trúc chi phí của việc đào tạo và suy luận AI thông qua một loạt đổi mới kiến trúc cơ bản và gián tiếp thúc đẩy việc hình thành một hệ sinh thái phần cứng mới. Từ MoE và MLA đến DSA, CSA, mHC, Engram, đến Dual Path và TileLang, lộ trình kỹ thuật của DeepSeek luôn xoay quanh một vấn đề cốt lõi: làm thế nào để chạy các mô hình mạnh hơn với sức mạnh tính toán cao cấp hơn khi HBM, các quy trình nâng cao, đóng gói và hệ sinh thái CUDA đều bị hạn chế.
Điều đáng chú ý nhất của bài viết không phải là "liệu DeepSeek có thể kiếm được hàng trăm triệu đô la từ API hay đăng ký hay không", mà là liệu nó có liên kết được khả năng của mô hình, hệ thống bộ nhớ và hệ sinh thái phần cứng trong nước với nhau hay không. Tính năng nén bộ nhớ đệm KV giúp giảm sự phụ thuộc vào HBM, NAND và SSD có thể thực hiện lưu vào bộ nhớ đệm dài hạn, LPDDR có thể được sử dụng để tải luồng trọng lượng và lưu trữ Engram, còn TileLang cố gắng làm suy yếu hào CUDA. Nếu những đổi mới này tiếp tục lan rộng, người hưởng lợi sẽ không chỉ là DeepSeek mà còn bao gồm bộ lưu trữ, ASIC, GPU, chip mạng và toàn bộ chuỗi cơ sở hạ tầng AI.
Tất nhiên, những nhận định trong bài viết về "sinh thái công nghiệp 10 nghìn tỷ USD" và "định giá 1 nghìn tỷ USD" vẫn mang tính suy luận mạnh mẽ. Nhưng nó cung cấp một con đường quan trọng để hiểu DeepSeek: nguồn mở không nhất thiết có nghĩa là từ bỏ thương mại hóa và giá thấp không nhất thiết chỉ trợ cấp cho thị trường. Đối với DeepSeek, hoạt động kinh doanh thực sự có thể không nằm ở lớp ứng dụng mà là giúp cung cấp nhiều phần cứng hơn và cung cấp AI với chi phí thấp hơn. Nói cách khác, thứ họ bán không nhất thiết phải là mô hình mà là tính khả thi của cơ sở hạ tầng AI thế hệ tiếp theo.
Sau đây là văn bản gốc:

Bạn đã bao giờ nghĩ về cách DeepSeek kiếm tiền và có thể là rất nhiều tiền chưa?
Nó không có gói đăng ký chương trình cạnh tranh như GLM, MoonShot và MiniMax; nó cũng không có mô hình đa phương thức, âm thanh hoặc video. Cho đến nay, nó thậm chí còn không có khai thác riêng, đó là khung vận hành bên ngoài để gọi mô hình, truy cập công cụ và thực thi nhiệm vụ—mặc dù gần đây họ đã bắt đầu tuyển dụng các vị trí liên quan để chuẩn bị xây dựng hệ thống này.
Đồng thời, DeepSeek dường như đã đứng về phía nguồn mở từ lâu, thậm chí còn sẵn sàng chia sẻ công khai những "bí mật" của mình. Đây không phải là điên rồ sao? Chẳng phải bạn đang đốt tiền một cách vô ích sao? Liệu các nhà đầu tư có sẵn sàng đổ 10 tỷ USD vào đó và ném tiền xuống cống không?
Cá nhân tôi nghĩ câu trả lời hoàn toàn ngược lại.
Tiếp theo, tôi sẽ đưa ra một số quan sát dựa trên những gì DeepSeek đã làm cho đến nay và phân tích bộ chiến lược mà nó dường như đang tuân theo. Mục tiêu của Giám đốc điều hành DeepSeek, Liang Wenfeng, có thể vượt xa sự cạnh tranh về mô hình trước mắt. Anh ta có thể đang hướng tới một giải thưởng lớn hơn: DeepSeek có cơ hội đạt mức định giá 1 nghìn tỷ USD, đồng thời thúc đẩy hình thành một ngành công nghiệp mới trị giá 10 nghìn tỷ USD.

TechInAsia Giới thiệu về DeepSeek Báo cáo về vòng cấp vốn mới nhất
Xem lại DeepSeek “Hành trình của anh hùng”
DeepSeek đã đi ngược chiều gió. Nó không chọn tiếp tục tung ra các mô hình mạnh mẽ hơn một chút rồi vội vàng đóng gói chúng thành các ứng dụng có thể kiếm tiền trực tiếp, chẳng hạn như các gói đăng ký lập trình. Vào ngày 27 tháng 1 năm 2025, tôi đã đăng một dòng tweet được lan truyền rộng rãi về “Hành trình của anh hùng” của DeepSeek trong mắt tôi. Bây giờ câu chuyện thậm chí còn thú vị hơn.
Trong khi những người khác vẫn đang cố gắng xây dựng các mô hình dày đặc thì DeepSeek đã chọn mô hình Hỗn hợp các chuyên gia (MoE), mô hình này khó đào tạo hơn.
Họ đã sử dụng phương pháp "nguyên tắc đầu tiên" để phát minh ra thuật toán GRPO mới nhằm thay thế thuật toán học tăng cường PPO vốn là xu hướng chủ đạo vào thời điểm đó nhưng thực hiện tốn kém hơn.
Họ nhận thấy rằng việc học tăng cường từ Phần thưởng đã được xác minh (RLVR) dựa trên phần thưởng có thể xác minh được là một chiến lược quan trọng để cải thiện khả năng suy luận của mô hình.
Họ cũng đề xuất một chiến lược giải mã suy đoán đơn giản thông qua "Dự đoán nhiều mã thông báo", chiến lược này cũng làm cho tín hiệu huấn luyện dày đặc hơn.
Họ đã cải tiến quy trình "Bong bóng KHÔNG" để cải thiện hiệu quả sử dụng các nguồn tài nguyên GPU hạn chế.
Họ đã phát hành một bộ cân bằng tải chuyên nghiệp để giúp mọi người triển khai các mô hình MoE dễ dàng hơn. Đặc biệt thông qua chiến lược "Song song chuyên gia rộng", mô hình có thể được phục vụ với lô lớn hơn, từ đó giảm đáng kể chi phí suy luận.
Họ đã phát minh ra các cơ chế như MLA, DSA, CSA, HCA, v.v. để giảm nhu cầu về KV Cache và giữ cho nhu cầu tính toán tăng lên khi độ dài ngữ cảnh tăng gần bằng hằng số nhất có thể.
Họ đã phát minh ra Engram để trao đổi bộ nhớ lấy hiệu quả tính toán.
Họ cũng phát minh ra MHC để có thể đào tạo ổn định khi mô hình mở rộng quy mô. Có rất nhiều ví dụ tương tự.
Trong cấu trúc tường thuật phổ biến nhất của “cuộc hành trình của người anh hùng”, người anh hùng không bao giờ quyết định ngay từ đầu cuộc hành trình của mình sẽ dẫn đến đâu. Trong quá trình học tập, anh dần dần phát hiện ra sứ mệnh thực sự vĩ đại của mình và hoàn thành nó dù gặp muôn vàn trở ngại. Anh sẽ gặp phải nhiều người nghi ngờ, nhưng anh chọn cách phớt lờ họ. Anh ta cũng sẽ gặp phải nhiều kẻ độc ác. Anh ấy có những sai sót hoặc khuyết điểm rõ ràng, nhưng cuối cùng anh ấy sẽ vượt qua chúng và hoàn thành sứ mệnh của mình. Anh ta phải đối mặt với những thách thức dường như không thể vượt qua, nhưng vẫn tìm cách thành lập liên minh và học cách sử dụng các nguồn tài nguyên quý giá và có hạn một cách khôn ngoan. Chính điều này khiến khán giả sẵn sàng cổ vũ cho người hùng. Đây là lý do tại sao DeepSeek đã giành được những người theo dõi, sự tôn trọng trên toàn cầu và cả những kẻ gièm pha.
Như tôi sẽ giải thích chi tiết tiếp theo, DeepSeek đã đi trên con đường này trong một thời gian dài và dần dần khám phá ra vận mệnh cuối cùng của mình: mục tiêu của nó không phải là bán các giải pháp đăng ký lập trình mà là thúc đẩy hệ sinh thái phần cứng AI của Trung Quốc trị giá 10 nghìn tỷ USD và đạt được mức định giá 1 nghìn tỷ USD. Trong quá trình này, nó cũng sẽ tạo cơ hội cho nhiều người mới tham gia vào hệ sinh thái phần cứng phương Tây.

Hãy bắt đầu với một số phép tính thú vị về Bộ đệm KV
Xem @SemiAnalysis_ Dòng tweet gần đây và kịp thời này:
DeepSeek đã giải quyết vấn đề này tốt hơn bất kỳ ai!
Trước tiên hãy thực hiện một số tính toán thú vị về KV Cache. Đừng lo lắng, sẽ không có vấn đề gì nếu bạn không thích môn toán. Chúng tôi sẽ sử dụng máy tính KV Cache được phát hành gần đây để xem DeepSeek V4 Pro có thể tiết kiệm được bao nhiêu KV Cache và so sánh nó với các mẫu GLM và Qwen mới nhất.
Ở đây tôi tính toán với độ dài ngữ cảnh là 1 triệu, giả sử độ chính xác của KV là 8 bit và độ chính xác của bộ chỉ mục là 16 bit. Bạn cũng có thể tự mở máy tính này và dùng thử: https://kvcache.ai/tools/kv-cache-computer/
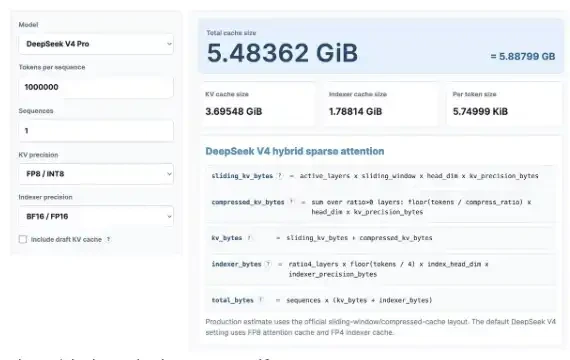
Bạn cũng có thể tự mở máy tính và dùng thử!
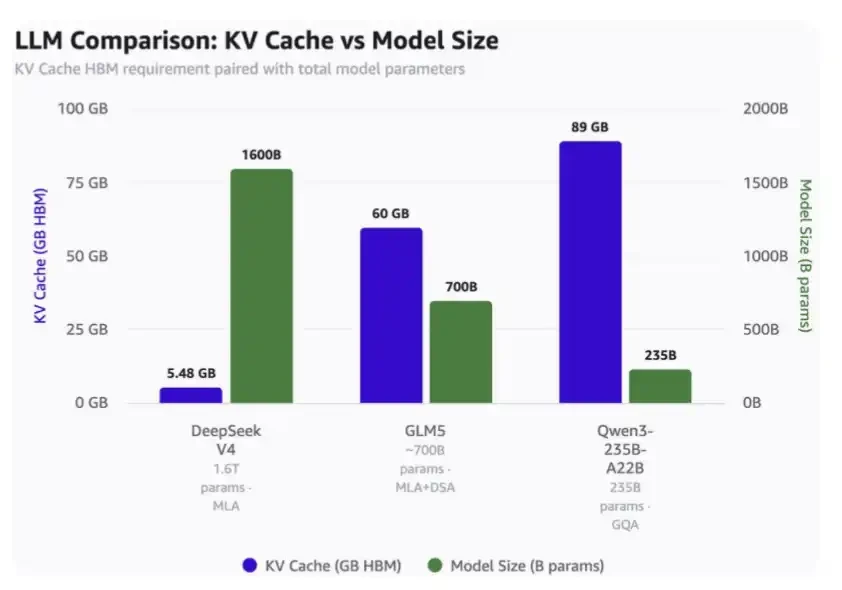
Với độ dài ngữ cảnh 1 triệu:
·DeepSeek V4 chỉ yêu cầu 5,48GB HBM;
·GLM-5 yêu cầu HBM 60GB;
·Qwen3-235B-A22B yêu cầu HBM lên tới 89GB.
Cần lưu ý rằng:
·DeepSeek là mô hình có 1,6 nghìn tỷ tham số;
·GLM-5 có khoảng 700 tỷ tham số và đã áp dụng MLA và DSA của DeepSeek nhưng chưa sử dụng cơ chế chú ý nén mới nhất;
·Qwen3-235B-A22B có khoảng 235 tỷ tham số, sử dụng cơ chế chú ý của GQA.
DeepSeek đã có những đóng góp cơ bản trong việc giảm bớt áp lực về trí nhớ. Nếu loại cải tiến này được áp dụng rộng rãi, nó sẽ giảm đáng kể chi phí hoạt động của các Đại lý dài hạn và mở ra hàng loạt kịch bản ứng dụng mới tiếp theo.
KV Cache dưới 1 triệu Token bối cảnh và quy mô mô hình So sánh tỷ lệ sử dụng
Phương pháp đằng sau "điên"
Lý do khiến KV Cache có thể nhỏ đến vậy mà không làm giảm chất lượng mô hình là vì sao DeepSeek có thể cung cấp bộ nhớ đệm dài hạn với mức giá rất thấp - giá của nó thậm chí còn thấp hơn 3% so với giá thành công của bộ nhớ đệm của Sonnet 4.6 và DeepSeek có thể giữ bộ nhớ đệm trong vài giờ.
Đối với các tác vụ có thời gian sử dụng lâu dài, KV Cache nhỏ hơn có nghĩa là chúng có thể được tải xuống ổ SSD một cách tiết kiệm hơn và được tải lại khi cần. Bằng cách này, sự phụ thuộc vào HBM có thể giảm bớt. Từ góc độ của ngành công nghiệp phần cứng AI của Trung Quốc, HBM không chỉ có nguồn cung khan hiếm mà còn là một trong những loại bộ nhớ khó sản xuất nhất.
Ngoài ra, DeepSeek đã phát triển công nghệ để tải KV Cache từ SSD nhanh hơn, được mô tả trong bài báo Đường dẫn kép của nó.
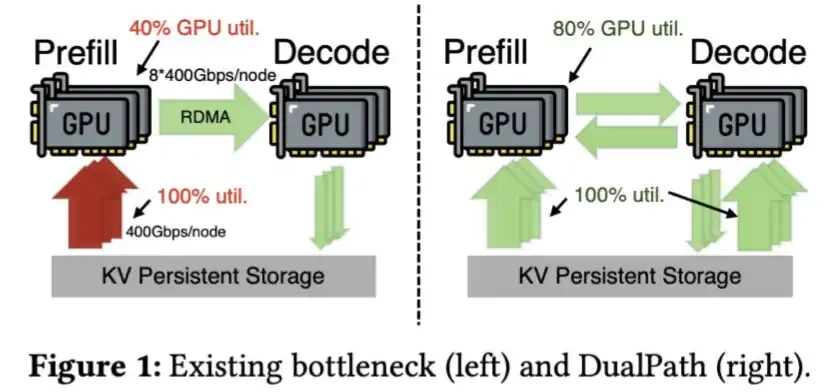
DeepSeek V4 nén KV Cache nhiều đến mức bước này thậm chí có thể không cần thiết.
Vậy ai là người hưởng lợi trực tiếp nhất từ việc nén KV Cache?
Ai đang cung cấp SSD trên quy mô lớn? Đừng quên, YMTC (Bộ nhớ Yangtze) đang phát triển thành một gã khổng lồ trong không gian 3D NAND. NAND giúp DeepSeek tránh tính toán KV hai lần. Đổi lại, DeepSeek đã tạo ra một thị trường khổng lồ cho NAND và SSD - điều này sẽ không chỉ mang lại lợi ích cho Bộ nhớ Yangtze mà còn cho các nhà sản xuất liên quan khác.

Tuy nhiên, vấn đề không chỉ là về NAND và SSD.
Bộ nhớ LPDDR cũng có tiềm năng lớn. Nó có thể đóng vai trò là nơi lưu trữ trọng lượng mô hình và truyền các trọng số này vào HBM khi cần, từ đó giảm bớt áp lực nhu cầu đối với HBM. Nhóm SGLang đã xuất bản một blog hay giới thiệu điều này. Hình ảnh dưới đây cho thấy cách thức hoạt động của chương trình này.
Mặc dù DeepSeek chưa đưa ra bất kỳ thiết kế cụ thể nào cho giải pháp này, nhưng kiến trúc MoE, số lượng lớn các mô hình chuyên gia và đặc điểm trọng lượng 4 bit của nó giúp triển khai giải pháp này dễ dàng hơn.
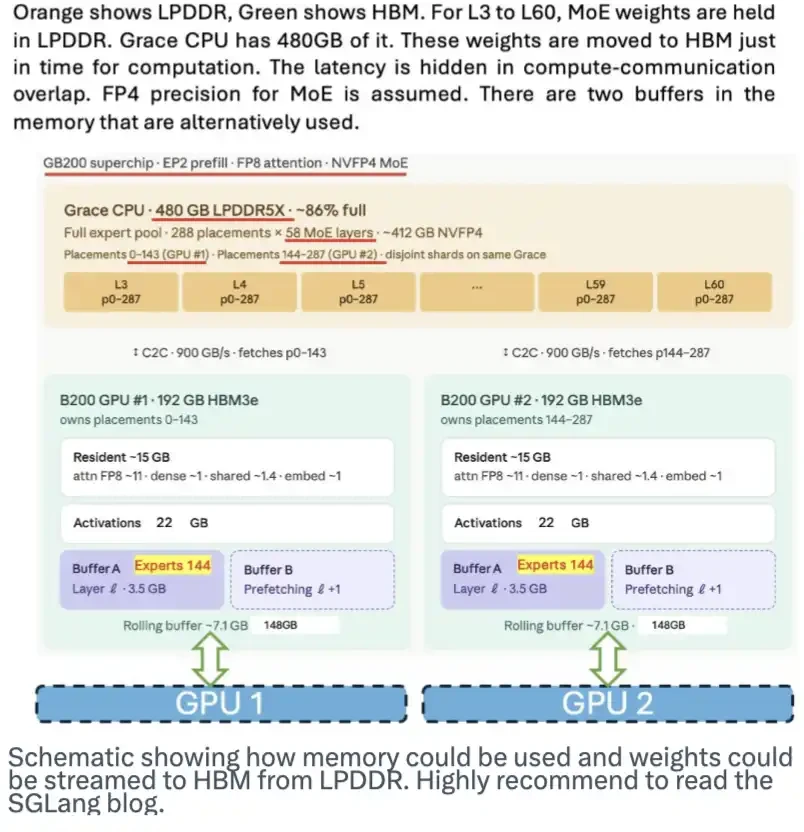
Sơ đồ này cho thấy cách sử dụng bộ nhớ và cách lấy trọng số mô hình từ Luồng LPDDR vào HBM. Tôi thực sự khuyên mọi người nên đọc blog của SGLang.
Sự đổi mới này, khi kết hợp với KV Cache cực kỳ nhỏ gọn và không mất dữ liệu, sẽ làm giảm đáng kể nhu cầu về HBM.
Vậy ai đang sản xuất LPDDR ở Trung Quốc? Câu trả lời chính là CXMT, tức là Changxin Storage. Họ chỉ chậm hơn nửa thế hệ về tốc độ LPDDR và một thế hệ về mật độ, đây không phải là một khoảng cách lớn.
Ngoài lượng NAND dồi dào, hệ sinh thái AI của Trung Quốc cũng sẽ có đủ nguồn cung LPDDR trong tương lai gần. Điều này có thể làm giảm bớt áp lực lên sức mạnh tính toán? Câu trả lời là: có. Đọc tiếp.

Việc sử dụng bộ nhớ thông minh cũng có thể giảm áp lực lên GPU / ASIC
Sử dụng NAND để lưu trữ KV Cache Chức năng này thực sự rất dễ hiểu: nó cho phép giữ lại KV Cache cho trong khoảng thời gian dài hơn, giảm áp lực lên HBM, đồng thời tránh các phép tính lặp lại của KV Cache, do đó giảm gánh nặng tính toán cho GPU và ASIC.
Vậy LPDDR có thể hoạt động theo cách tương tự không? Ngoài việc là một vị trí lưu trữ có thể truyền trọng số tới HBM "theo yêu cầu", liệu nó có thể giảm thêm áp lực tính toán không?
Câu trả lời là: có.
LPDDR có thể được sử dụng để lưu trữ lượng lớn nội dung được gọi là Engram. Trong bài viết Engram của DeepSeek, họ chỉ ra rằng MoE có thể mở rộng công suất mô hình thông qua các phép tính có điều kiện, nhưng bản thân Transformer thiếu cơ chế "tìm kiếm kiến thức" vốn có. Vì vậy, Transformer thường phải tính toán mô phỏng quá trình truy xuất không hiệu quả.
Để giải quyết vấn đề này, DeepSeek đã đề xuất mô-đun Engram. Nó hiện đại hóa việc nhúng N-gram cổ điển vào cơ chế tra cứu O(1) dựa trên hàm băm, từ đó tạo ra một đường dẫn phân tán bổ sung mà họ gọi là bộ nhớ có điều kiện.
Phương pháp này có thể lưu các phép tính nhưng cũng yêu cầu bộ nhớ để lưu trữ bảng nhúng, bản thân bảng này có thể rất lớn.
Về cơ bản, đây là một giải pháp "bộ nhớ cho tính toán" điển hình. Nhưng cái nhìn sâu sắc quan trọng của nó là: từ góc độ chi phí đọc dữ liệu trên mỗi bit, phía "bộ nhớ" rẻ hơn nhiều - việc tra cứu LPDDR rẻ hơn nhiều so với việc để dữ liệu đi qua nhiều lớp Máy biến áp để thực hiện phép tính chuyển tiếp. Vì vậy, trong một kịch bản quy mô lớn, đó là một thỏa thuận rất tốt.
Đây là cách DeepSeek hy sinh một số bộ nhớ để đổi lấy tiết kiệm điện toán.
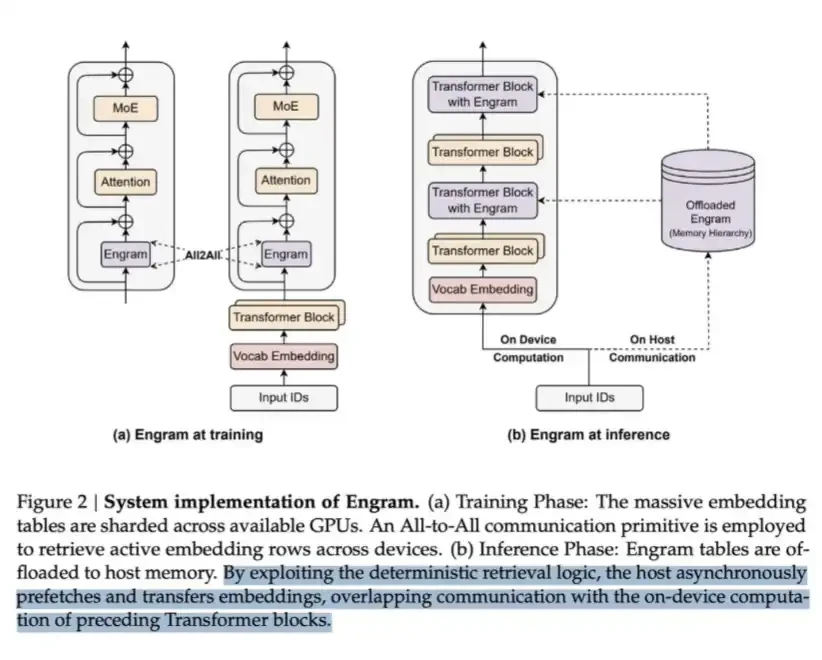
Một sự đánh đổi đáng thực hiện
Không có mật độ bóng bán dẫn chip tương đương và không có EUV, GPU và ASIC của Trung Quốc đang chạy ở FLOP thô. Về sức mạnh tính toán, rất có thể tụt hậu so với GPU phương Tây trong một thời gian dài. Họ cũng vẫn còn những lỗ hổng đáng kể trong việc đóng gói tiên tiến. Do đó, những sự đánh đổi này rất đáng thực hiện, đặc biệt nếu Trung Quốc có thể sản xuất hàng loạt bộ nhớ NAND và LPDDR.
Xem xét chiến lược dài hạn của DeepSeek
Đánh giá từ những đổi mới này, mục tiêu của DeepSeek dường như không phải là kiếm được hàng trăm triệu đô la lợi nhuận ngay bây giờ. Nhiều lựa chọn mà nó đã đưa ra trước đây minh họa cho điểm này: cho đến nay, không có đa phương thức, không có mô hình giọng nói và mô hình video là không thể.
Những gì nó thực sự tham gia là một trò chơi dài hạn, kiên nhẫn có thể đạt tới 10 nghìn tỷ USD: thúc đẩy hình thành một hệ sinh thái phần cứng AI thay thế.
Điều này không chỉ cho phép các nhà sản xuất bộ nhớ Trung Quốc trở thành những nhân tố chủ chốt ở Trung Quốc và thị trường phần cứng AI toàn cầu mà còn giúp giảm căn bản các yêu cầu về tài nguyên và giúp việc đào tạo cũng như dịch vụ của các mô hình AI tiết kiệm chi phí hơn. Bằng cách này, nhiều nhà sản xuất GPU, ASIC và nhà sản xuất chip mạng có cơ hội trở thành những lựa chọn khả thi.
Đồng thời, những đổi mới này cũng sẽ mang lại lợi ích cho hệ sinh thái nguồn mở phương Tây và thế hệ nhà sản xuất phần cứng mới.
Thực ra tất cả các dấu hiệu đều ở đó. Chúng tôi cũng có thể xem xét chi tiết những đổi mới mà DeepSeek đã đề xuất cho đến nay:
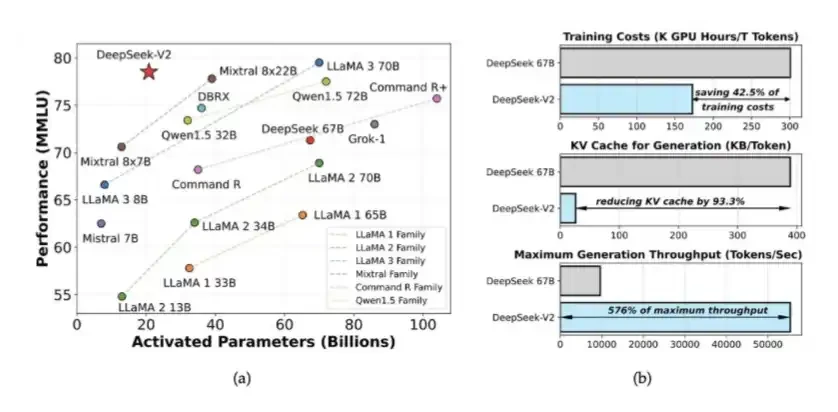
1. Sự kết hợp giữa các chuyên gia (MoE) và MLA được giới thiệu trong DeepSeek V2
DeepSeek đã giới thiệu MoE và MLA trong V2. MoE giảm lượng tính toán cần thiết để đào tạo các mô hình có độ thông minh cao khoảng 40% đến 50%; MLA giảm 90% bộ đệm KV.
Điều này làm cho việc tải KV Cache sang SSD khá hiệu quả.
Những ý tưởng này lần đầu tiên xuất hiện trong bài báo DeepSeek V2 do DeepSeek phát hành vào tháng 5 năm 2024. Sau đó, chúng cũng đặt nền móng cho việc đào tạo DeepSeek V3. Vào thời điểm đó, DeepSeek chỉ sử dụng 2048 GPU H800 có hiệu suất yếu hơn để huấn luyện một hệ thống có hiệu suất gần ngang bằng với các mô hình nguồn đóng.
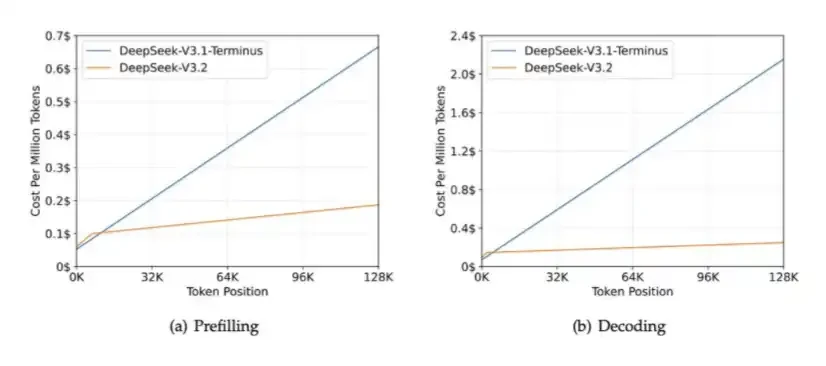
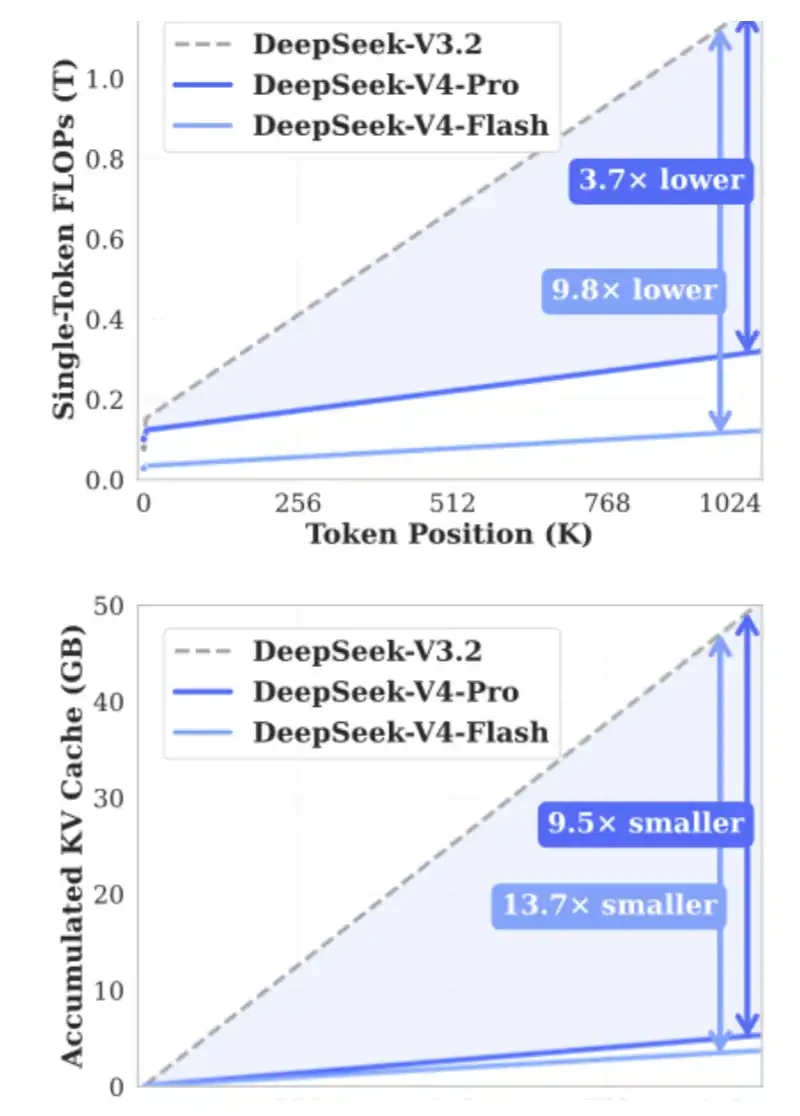
2. DSA: Được giới thiệu trong DeepSeek V3.2 Exp để giảm chi phí tính toán trong các tình huống ngữ cảnh dài đồng thời giảm bớt áp lực băng thông HBM.
Vai trò cốt lõi của DSA là đảm bảo rằng số lượng tính toán không tiếp tục tăng khi độ dài ngữ cảnh tăng lên. Bạn có thể xem biểu đồ bên dưới: Khi độ dài ngữ cảnh tăng lên, thời gian xử lý của DeepSeek-V3.2 về cơ bản vẫn ổn định.
3. mHC: DeepSeek đã được đề xuất trong bài báo "mHC: Siêu kết nối bị ràng buộc đa dạng" vào tháng 12 năm 2025.
mHC là một cải tiến của DeepSeek ở cấp độ kiến trúc vĩ mô, giúp thiết kế lại cách truyền thông tin giữa các lớp Transformer.
Trước đây, kể từ ResNet, các mô hình thường sử dụng kết nối dư tiêu chuẩn, đó là x + F(x). Những gì MHC làm là mở rộng luồng dư thành nhiều kênh thông tin song song và cho phép mô hình thực hiện việc trộn có thể học được giữa các kênh này. Điều quan trọng là nó ràng buộc ma trận trộn thành ma trận hai ngẫu nhiên, nghĩa là thành khối đa diện Birkhoff thông qua phép chiếu Sinkhorn-Knopp. Bằng cách này, về mặt toán học đảm bảo rằng biên độ tín hiệu vẫn ổn định cho dù mô hình được xếp chồng sâu đến đâu.
Điều này giải quyết vấn đề mất ổn định thảm khốc mà trước đây các Siêu kết nối không bị ràng buộc phải đối mặt. Siêu kết nối ban đầu được ByteDance đề xuất, nhưng nếu không có ràng buộc, khả năng khuếch đại tín hiệu sẽ tăng vọt lên 3.000 lần trên quy mô 27 tỷ thông số, cuối cùng dẫn đến việc đào tạo hoàn toàn sụp đổ.
Chi phí tính toán của mHC rất thấp: nó chỉ chiếm khoảng 6,7% tổng thời gian đào tạo thực tế vì nó không thay đổi FLOP của lớp chú ý hoặc lớp FFN, cũng như cách định tuyến đầu ra của các lớp này giữa các lớp.
Nhưng sự cải thiện hiệu suất mà nó mang lại khá rõ ràng: ở quy mô 27 tỷ tham số, mHC cải thiện 7,2 điểm trong nhiệm vụ lý luận BIG-Bench Hard, 3,2 điểm trong nhiệm vụ DROP, 2,8 điểm trong nhiệm vụ toán học GSM8K và 1,4 điểm trong nhiệm vụ kiến thức chung MMLU. Những cải tiến này đạt được với cùng kích thước mô hình và ngân sách tính toán gần như giống nhau.
Về cơ bản, mHC đạt được mức độ thông minh cao hơn trên mỗi thông số mà hầu như không cần FLOP bổ sung bằng cách cung cấp cho mạng cấu trúc liên kết định tuyến thông tin xuyên lớp phong phú hơn, biểu cảm hơn.
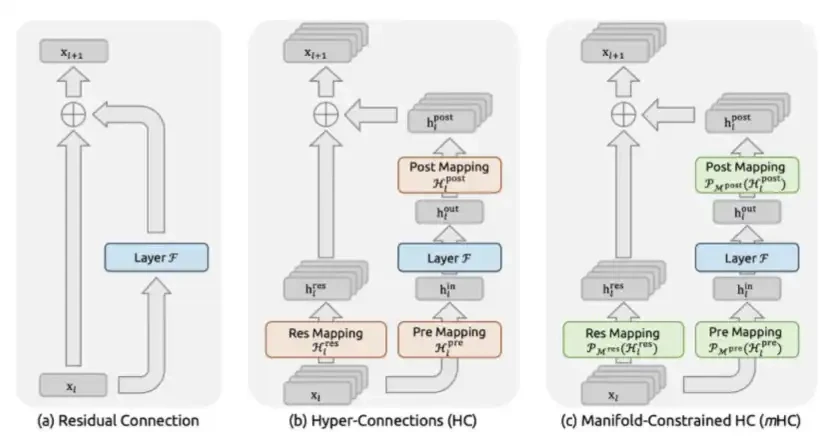
mHC Đây là một thiết kế kiến trúc phức tạp nhưng có thể mang lại quy trình đào tạo ổn định hơn và thông số đơn vị thông minh cao hơn.
4. CSA, HSA: DeepSeek sẽ được giới thiệu trong phiên bản V4 vào tháng 4 năm 2026.
Mục tiêu của CSA và HSA là giảm thêm 90% yêu cầu về Bộ nhớ đệm KV bằng cách nén Mã thông báo KV và giảm đáng kể FLOP cần thiết, từ đó đồng thời giảm bớt áp lực lên HBM và GPU/ASIC.
5. Engram: DeepSeek sẽ được giới thiệu vào quý đầu tiên của năm 2026. Về cơ bản, nó sử dụng bộ nhớ, tức là bộ nhớ LPDDR, ở một mức độ nào đó để đổi lấy hiệu quả tính toán.
Như được hiển thị trong biểu đồ chi tiết bên dưới, Engram mang lại những cải tiến hiệu suất đáng kể với tổng ngân sách tham số như nhau.
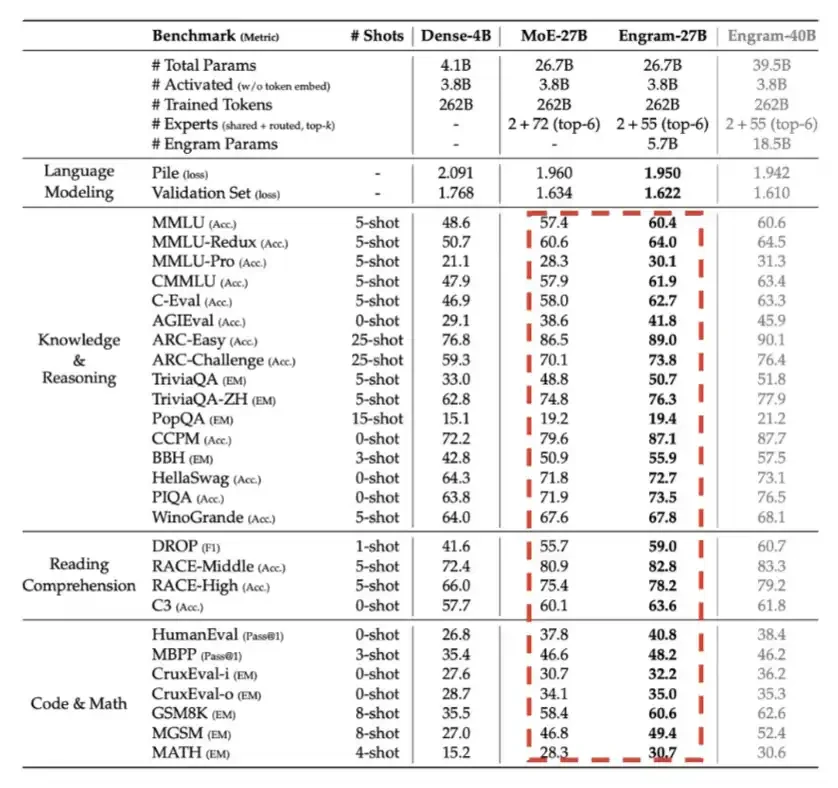
6. Engram: DeepSeek sẽ được giới thiệu vào quý 1 năm 2026, về cơ bản là sử dụng bộ nhớ ở một mức độ nào đó, tức là bộ nhớ LPDDR để đổi lấy hiệu quả tính toán.
Như được hiển thị trong biểu đồ chi tiết bên dưới, Engram mang lại những cải tiến hiệu suất đáng kể với tổng ngân sách tham số như nhau.

Đây là đề xuất được DeepSeek chia sẻ với các nhà sản xuất phần cứng trong bài báo V4. Tôi khá chắc chắn rằng họ sẽ đưa ra nhiều phản hồi hơn nữa khi tương tác ngoại tuyến.
7. Việc đầu tư vào TileLang cũng đi theo hướng tương tự: DeepSeek không chỉ giải quyết nút thắt về sức mạnh tính toán của chính mình mà còn thúc đẩy khả năng hệ sinh thái phần cứng của Trung Quốc cạnh tranh với hệ sinh thái phương Tây.
Với TileLang, các nhà phát triển có thể viết kernel, là mã cơ bản cho máy tính, một lần và sau đó cho phép nó chạy thành công trên nhiều nền tảng phần cứng, miễn là các nền tảng này có hỗ trợ phụ trợ TileLang tương ứng.
Tôi mong đợi các phòng thí nghiệm AI khác của Trung Quốc sẽ tham gia. Điều này sẽ giúp các nhà sản xuất phần cứng Trung Quốc đối phó với cái gọi là "hào CUDA" một cách gián tiếp. Đồng thời, nó cũng sẽ mở ra tiềm năng của nhiều phần cứng phương Tây hơn, chẳng hạn như AMD.
Cần lưu ý rằng nhiều nền tảng phần cứng AI ở Trung Quốc đã cung cấp khả năng tương thích CUDA hoặc lớp dịch CUDA. Ví dụ: Moore Thread, Muxi, Biren và Tianshu Zhixin đều là những nhà sản xuất chip Trung Quốc đạt được khả năng tương thích CUDA cao thông qua lớp dịch. Vì vậy về mặt lý thuyết, họ không nhất thiết cần đến TileLang.

Học tăng cường và RSI trên quy mô lớn
Với DeepSeek Với nhiều nguồn sức mạnh tính toán sẵn có hơn, tức là có nhiều phần cứng tùy chọn hơn và giảm nhu cầu về tài nguyên máy tính từ chính mô hình, nó có thể thúc đẩy nhiều hơn nữa các dự án đào tạo đầy tham vọng, đặc biệt là đào tạo học tập sau củng cố.
Học tăng cường yêu cầu tạo ra một số lượng lớn quỹ đạo, tức là tạo ra hàng nghìn tỷ Token. Quá trình này có thể nhanh chóng trở nên cực kỳ tốn kém. Hơn nữa, nếu bạn muốn đào tạo một mô hình có độ dài ngữ cảnh là 1 triệu, bạn cần tạo ra các quỹ đạo có cùng độ dài. Chỉ bằng cách huấn luyện mô hình theo những quỹ đạo siêu dài như vậy thì các nhiệm vụ dài hạn mới có thể thực sự được hỗ trợ.
Ngoài ra, do sự gia tăng các tùy chọn phần cứng, DeepSeek sẽ có nhiều tài nguyên phần cứng hơn để sử dụng, điều này sẽ thúc đẩy nghiên cứu tự động, còn được gọi là RSI. RSI đề cập đến việc AI tự thiết kế và thực hiện các thử nghiệm. Cách tiếp cận này bao gồm rất nhiều thử nghiệm và sai sót, đồng thời chi phí có thể tăng lên nhanh chóng. Nhưng RSI rất quan trọng để khám phá không gian thiết kế mô hình hoàn chỉnh. Trước khi chuyển sang AGI và sau đó là ASI, DeepSeek phải có khả năng RSI.
Những gì DeepSeek đang làm hôm nay, toàn bộ ngành sẽ làm theo vào ngày mai
Những đổi mới của DeepSeek xung quanh các mô hình hỗn hợp chuyên gia, MLA, DSA và các hướng khác đã được các phòng thí nghiệm AI khác trên thế giới và Trung Quốc áp dụng.
Ví dụ: ZAI, nhà phát triển dòng mô hình GLM, sử dụng MLA và DSA. Kimi, còn được gọi là Moonshot, cũng sử dụng MLA và không ngại nói rằng kiến trúc của nó dựa trên kiến trúc DeepSeek. Đổi lại, DeepSeek sử dụng trình tối ưu hóa Muon, được Kimi (Moonshot) áp dụng lần đầu tiên để đào tạo quy mô lớn.
Cần lưu ý rằng:
MoE được Google đề xuất lần đầu tiên vào năm 2017 và tác giả chính là Noam Shazeer. Đóng góp của DeepSeek nằm ở việc áp dụng MoE trên quy mô lớn và phát minh ra các kỹ thuật hỗ trợ của riêng mình.
Muon, MomentUm được trực giao hóa bởi trình tối ưu hóa Newton-Schulz, được nhà nghiên cứu máy học Keller Jordan đề xuất vào cuối năm 2024. Nhóm Kimi (Moonshot) là nhóm đầu tiên sử dụng nó để đào tạo quy mô lớn.
Còn vấn đề kiếm tiền thì sao?
Chúng ta có thể xem OpenAI là một ví dụ thú vị.
OpenAI đã nhận được giấy phép/quyền chọn mua cổ phần của AMD và Cerebras với giá thấp hơn, với các quyền gắn liền với các mốc quan trọng trong mức tiêu thụ điện năng tính toán của nó. Đây là một thương vụ rất tốt cho AMD và Cerebras. Bởi vì một khi OpenAI cam kết sử dụng phần cứng của họ, khả năng thành công lâu dài của họ sẽ tăng lên đáng kể.
Có đoạn này trong thông báo của AMD:
"Là một phần của thỏa thuận và để gắn kết hơn nữa lợi ích chiến lược của cả hai bên, AMD đã ban hành bảo đảm cho OpenAI mua tới 160 triệu cổ phiếu phổ thông của AMD. Cổ phiếu này sẽ được trao dần dần dựa trên việc đạt được một số cột mốc nhất định. Đợt đầu tiên sẽ được trao khi quá trình triển khai 1 GW ban đầu hoàn tất và các đợt tiếp theo sẽ được trao dần dần khi quy mô mua sắm mở rộng lên 6 GW. cũng nhất quán với việc AMD Linked đáp ứng các mục tiêu giá cổ phiếu cụ thể và OpenAI đạt được các cột mốc kỹ thuật và thương mại cần thiết để cho phép AMD triển khai trên quy mô lớn. Tôi kỳ vọng DeepSeek sẽ làm được điều đó. Chúng tôi cũng sẽ đạt được các thỏa thuận tương tự với một số nhà sản xuất bộ nhớ, ASIC, CPU và công nghệ mạng của Trung Quốc, đồng thời hợp tác chuyên sâu với họ để làm cho các hệ thống phần cứng của các nhà sản xuất này có khả năng dẫn đầu khối lượng công việc AI. 10 nghìn tỷ USD, phương pháp "thu được lợi nhuận từ cổ phần thông qua hợp tác" sẽ mang lại cho DeepSeek cơ hội giúp Trung Quốc xây dựng một ngành công nghiệp khổng lồ không kém và chia sẻ chiếc bánh của riêng mình trong đó, cuối cùng đạt được mức định giá 1 nghìn tỷ USD.
Điều này không chỉ cho phép DeepSeek kiếm được nhiều tiền hơn hoạt động kinh doanh đăng ký ứng dụng truyền thống mà còn đạt được mục tiêu "làm cho AGI mang lại lợi ích cho mọi người".
Nếu bạn nhìn lại mọi thứ mà DeepSeek đã làm cho đến nay thì đây là lời giải thích hợp lý nhất
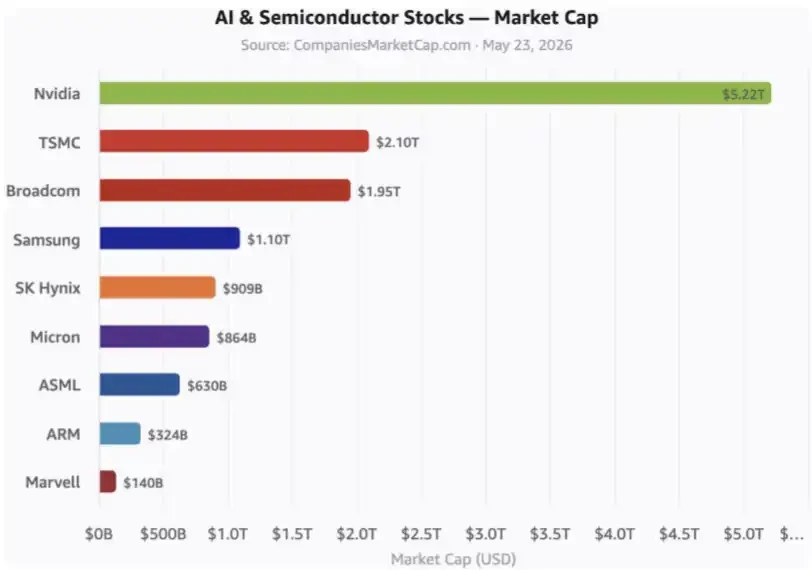
Đây là những điều sau đây. Các cổ phiếu AI quan trọng Không có trong hình là các công ty siêu quy mô, nhà cung cấp đám mây siêu quy mô và nhiều công ty liên quan khác
