
Decegeek's Lillion Lillion พาธ: ทําลายล้านล้านของระบบนิเวศฮาร์ดแวร์ที่มีโอเพนซอร์ส
นําการจัดเก็บในประเทศมากขึ้น ชิปและผู้ผลิตเครือข่ายเข้าไปในโครงสร้างพื้นฐาน AI โดยลดการฝึกอบรมและการให้เหตุผล

ชื่อเดิม: ดีพซีก 10 ตามรอย USD Grand statry
ต้นฉบับโดย: @ookwork menu
ต้นฉบับโดยเพ็กกี้ บล็อกบีทส์
สื่อมวลชน: ระหว่าง ปี ที่ ผ่าน มา การ ถก กัน เรื่อง ดีพ ซีก มี จุด รวม อยู่ ที่ การ แสดง แบบ, กลยุทธ์ เปิด แหล่ง และ สงคราม ราคา. แต่ถ้าวิธีเดียวที่จะเข้าใจดีพซีคคือ "ยอมหรือไม่สมัคร" "คุณมีนางแบบ" "คุณอยากทํามั้ย"。
บทความนี้นําเสนอการตัดสินที่เข้มงวดกว่า: เป้าหมายของดีพซีก'สไม่ได้จําเป็นในการตระหนักระยะสั้น ผ่านชั้นโปรแกรม แต่เพื่อการบูรณะเอไอ'ค่าใช้จ่ายโครงสร้างของค่าใช้จ่ายของการฝึกอบรมและเหตุผล จาก MoE, MLA, ถึง DSA, CSA, MHC, Engraphy, To Dual Path and Plancylang, Look Season's Telection. เส้นทางเทคนิคของ Depseck ได้ถูกดัดแปลงรอบ ๆ ประเด็นหลัก: จะรันแบบจําลองที่แข็งแรงขึ้นอย่างไร ด้วยคอมพิวเตอร์ที่มีคุณภาพสูงน้อยกว่าเมื่อ HBM, การเขียนโปรแกรมขั้นสูง, การบรรจุ และระบบนิเวศ CUDA ถูกจํากัด。
บทความ นี้ น่า สนใจ ที่ สุด ไม่ ว่า ดีพ ซีก จะ สามารถ หา เงิน ได้ หลาย ร้อย ล้าน ดอลลาร์ จาก API หรือ การ บอก รับ แต่ ไม่ ว่า จะ เป็น ความ สามารถ ใน การ เชื่อม โยง กัน, ระบบ ความ จํา, และ ระบบ นิเวศ ของ อุปกรณ์ สื่อสาร แห่ง ชาติ. KV การบีบข้อมูลแคชลดความไว้วางใจของ HBM, NAND และ SSD สามารถดําเนินการแคชระยะยาวได้, LPDDR สามารถใช้สําหรับการโหลดแบบหนักและบรรจุเอนแกรม, และพาเนลแลงพยายามที่จะทําให้คูน้ํา CUDA อ่อนแอลง ถ้านวัตกรรมเหล่านี้ยังคงแพร่กระจายต่อไป เครื่องราชอิสริยาภรณ์นี้ไม่ใช่แค่ดีพซีกเท่านั้น แต่ยังรวมถึงคลังสินค้า, ASAIC, GPU, เว็บชิป และห่วงโซ่พื้นฐาน AI ทั้งหมด。
แน่ ละ คํา ตัดสิน ใน ข้อ ความ ที่ ว่า “10 ล้าน ล้าน ดอลลาร์ ใน ระบบ นิเวศ อุตสาหกรรม ” และ “1 ล้าน ล้าน ดอลลาร์ ใน การ ประเมิน ” ยัง คง มี น้ํา เสียง ที่ น่า ทึ่ง กว่า. แต่ หนังสือ เล่ม นี้ ให้ แนว ทาง สําคัญ ที่ จะ เข้าใจ ลึก ซึ้ง ยิ่ง ขึ้น: แหล่ง ที่ เปิด เผย ไม่ จําเป็น ต้อง หมาย ถึง การ เลิก ค้า ขาย และ ราคา ไม่ จําเป็น ต้อง เป็น แค่ ตลาด ย่อย. สําหรับ ดีพ ซีค ธุรกิจจริงอาจไม่ได้อยู่ในระดับโปรแกรม แต่ช่วยเพิ่มเติมฮาร์ดแวร์ และทําให้มันสามารถจัดหา AI ได้ต่ํามากขึ้น พูด อีก อย่าง หนึ่ง ก็ ไม่ จําเป็น ต้อง มี การ ขาย แบบ จําลอง นั้น เอง แต่ ความ สามารถ ของ โครง สร้าง เอ ไอ รุ่น ต่อ ไป。
ต่อ ไป นี้ เป็น ข้อ ความ เดิม:

คุณเคยคิดบ้างไหมว่า ดีพซีคทําเงินได้มากแค่ไหน และทําเงินได้มากขนาดไหน
มันไม่ได้แนะนําสมาชิกโปรแกรมการแข่งขันเช่น GLM, Moonshot และ Mini Max; และมันไม่มี mulmodiar, เสียง, โมเดลวิดีโอ ถึงตอนนี้ มันยังไม่มีตัวควบคุมตัวเองด้วยซ้ํา โครงข่ายปฏิบัติการภายนอก สําหรับโมเดลโทร แม้ ว่า เมื่อ เร็ว ๆ นี้ พวก เขา ได้ เริ่ม สมัคร เข้า รับ ตําแหน่ง ที่ เกี่ยว ข้อง แต่ พวก เขา ก็ กําลัง เตรียม การ สร้าง ระบบ นี้。
ขณะเดียวกัน ดีพซีกดูเหมือนจะได้นานในด้านข้างของโอเพนซอร์ส, แม้ยินดีที่จะแบ่งปันความลับของเขาอย่างเปิดเผย ไม่บ้าเหรอ? มันไม่เกี่ยวกับการเผาเงินโดยเปล่าประโยชน์เหรอ นักลงทุนที่ลงทุนไป หนึ่งหมื่นล้านดอลลาร์ในนั้น กําลังโยนเงินลงท่อน้ําทิ้ง
โดยส่วนตัวแล้ว ฉันคิดว่าคําตอบมันตรงกันข้าม。
ต่อไป ผมจะตั้งข้อสังเกต จากสิ่งที่ ดีพซีก ได้ทํามา และวิเคราะห์ เป้าหมายของCEO ดีพซีก อาจมากกว่าการแข่งขันตัวอย่างในปัจจุบัน เขาเล็งไปที่รางวัลใหญ่: ดีพซีกมีโอกาสได้ตี 1,000,000 ล้านบาท ในขณะที่ขับรถอุตสาหกรรมใหม่ของ $ 10 ล้านล้าน。

เทคอินเชีย ที่ ดีพซีค ล่าสุดของการเงิน
Recisit Depeek's "ทริปฮีโร่"
ดีพ วิค วิ่งสู้กับลม ไม่ ได้ เลือก ที่ จะ ออก แบบ แบบ จําลอง ที่ แข็ง แรง กว่า เล็ก น้อย ต่อ ไป และ แล้ว ก็ กระตือรือร้น ที่ จะ บรรจุ โปรแกรม นั้น ไว้ เป็น โปรแกรม ที่ รู้ จัก โดย ตรง เช่น การ บอก รับ. วันที่ 27 มกราคม 2025 ผมส่งทวีตกระจายออกไปอย่างกว้างขวาง เกี่ยวกับ "การเดินทางของดีพซีค" ปัจจุบัน เรื่อง นี้ น่า สนใจ ยิ่ง ขึ้น。
ขณะ ที่ คน อื่น ๆ ยัง คง พยายาม จะ สร้าง แบบ จําลอง ที่ มี น้ํา หนัก ดีพ ซีก ได้ เลือก รุ่น ผสม พันธุ์ ที่ มี ความ ชํานาญ มาก กว่า (Mixture of Express, MoE)。
โดยใช้วิธีการ "หลักการแรก" พวกเขาคิดค้นอัลกอริทึม GRPO ใหม่ เพื่อแทนที่อัลกอริทึมหลัก ๆ ที่ PPO ค่าใช้จ่ายมากขึ้น。
พวก เขา พบ ว่า การ เรียน รู้ อย่าง เอา จริง เอา จัง โดย อาศัย ผล ตอบ แทน ที่ น่า เชื่อ ถือ (การ เรียน รู้ ที่ เสริม สร้าง จาก เรเน วา นส์, อาร์ แอล วี อาร์) เป็น วิธี หลัก ใน การ หา เหตุ ผล แบบ เสริม สร้าง。
นอก จาก นั้น พวก เขา ยัง เสนอ การ คาด คะเน ง่าย ๆ ว่า ด้วย กลยุทธ์ การ ถอด รหัส ผ่าน ทาง การ แสดง อุปไมย หลาย หลาก ขณะ เดียว กัน ก็ ทํา ให้ สัญญาณ ฝึก อบรม หนัก ขึ้น。
พวกเขาได้ปรับปรุงสายศูนย์ฟอง เพื่อปรับปรุงประสิทธิภาพของทรัพยากร GPU จํากัด。
พวกเขาปล่อยเครื่องชั่งน้ําหนักผู้เชี่ยวชาญ เพื่อให้ง่ายต่อการใช้รุ่นโมอี โดยเฉพาะอย่างยิ่งผ่าน กลยุทธ์ "Wide expect parts" แบบจําลองสามารถให้บริการด้วยนาฬิกาขนาดใหญ่ ซึ่งเป็นการลดค่าใช้จ่ายในการให้เหตุผลอย่างมาก。
พวกเขาได้คิดค้นกลไกเช่น MLA, DSA, CSA, HCA เพื่อลดความต้องการแคชของ KV 's และเพื่อให้เป็นค่าคงที่ที่เป็นไปได้ ความต้องการคํานวณเพิ่มขึ้นเป็นความยาวของบริบทเพิ่มขึ้น。
พวกเขาคิดค้น Engram เพื่อแลกเปลี่ยนหน่วยความจํา สําหรับการคํานวณมีประสิทธิภาพ。
นอกจากนี้ เขายังได้ประดิษฐ์ mHCs เพื่อช่วยให้การฝึกการแทงเข็มได้อย่างต่อเนื่อง มี หลาย ตัว อย่าง คล้าย ๆ กัน。
ในโครงสร้างของ "การเดินทางของฮีโร่" ส่วนมาก วีรบุรุษไม่เคยตัดสินใจ จากจุดเริ่มต้นว่าการเดินทางของพวกเขาจะนําไปที่ไหน เขา ได้ เรียน รู้ ตลอด เส้น ทาง การ เดิน ทาง ของ เขา เพื่อ ค้น พบ ภารกิจ ที่ แท้ จริง และ ใหญ่ ยิ่ง และ เพื่อ บรรลุ ผล สําเร็จ ภาย ใต้ อุปสรรค หลาย อย่าง. เขา จะ พบ กับ ผู้ สงสัย หลาย คน แต่ เขา เลือก ที่ จะ ไม่ สนใจ พวก เขา. นอก จาก นั้น เขา จะ พบ กับ นัก แสดง ที่ มุ่ง ร้าย หลาย คน. เขามีความบกพร่องอย่างชัดเจนหรือโรคภูมิแพ้ แต่ในที่สุดก็เอาชนะพวกเขา และเติมเต็มภารกิจของเขา เมื่อ เผชิญ กับ ข้อ ท้าทาย ที่ ดู เหมือน ไม่ มี ทาง แก้ เขา สามารถ หา วิธี ที่ จะ สร้าง พันธมิตร และ เรียน รู้ วิธี ใช้ ทรัพยากร ที่ หา ยาก และ มี ค่า อย่าง สุขุม. นั่นคือสิ่งที่ทําให้ผู้ชม ยินดีเชียร์วีรบุรุษ นี่ คือ เหตุ ผล ที่ ดี ลึก ซีก ชนะ ผู้ ติด ตาม, ความ นับถือ และ การ ต่อ ต้าน ทั่ว โลก。
อย่างที่ดิฉันจะอธิบายในรายละเอียด ดีพซีคอยู่บนท้องถนนมานาน และได้ค่อยๆค้นพบชะตากรรมสูงสุดของเขา เป้าหมายของมันไม่ใช่เพื่อขายสมาชิกโปรแกรม แต่เพื่อส่งเสริมระบบนิเวศของ AI ราคา 10 ล้านล้านดอลลาร์ของจีน ในกระบวนการนี้ มันยังจะสร้างโอกาส สําหรับผู้ติดตามใหม่ ๆ ในระบบนิเวศของฮาร์ดแวร์ตะวันตก。

เริ่มด้วยการคํานวณแคชของ KV ที่น่าสนใจ
@ Semianaysis ทวีตล่าสุด:
ดีพพิกแก้ปัญหาได้ดีกว่าใคร
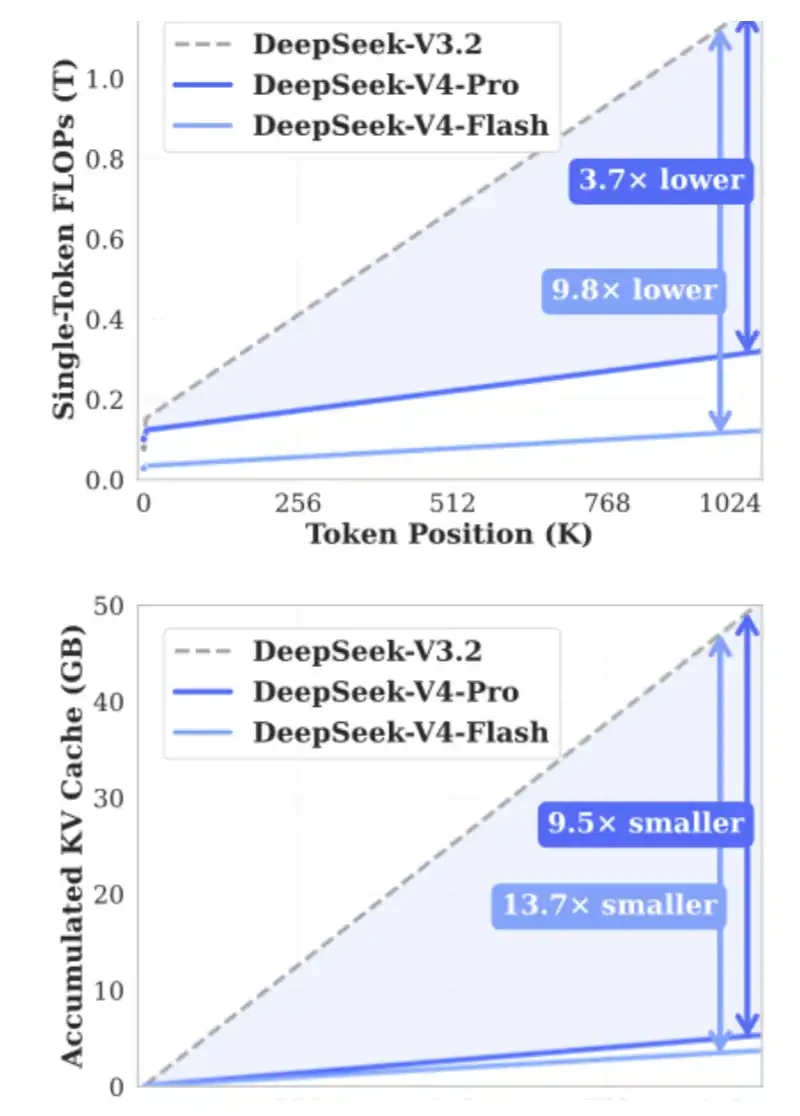
ลองเริ่มด้วยการคํานวณแคชของเควีที่น่าสนใจ ไม่ต้องห่วง ถึงแม้ว่าคุณจะไม่ชอบคณิตศาสตร์ เราจะใช้เครื่องคิดเลขแคชของ KV เพื่อดูว่าแคชของ KV สามารถนํามาได้มากน้อยแค่ไหน กับดีพซีก V4 โปร และเปรียบเทียบมันกับรุ่น GLM และ Qwan。
ตรงนี้ผมคํานวณด้วยความยาว 1 ล้านบริบท โดยสมมุติว่า KV คือ 8 บิต และตัวทําดัชนีคือ 16 บิต คุณสามารถลองเครื่องคิดเลขนี้ด้วยตัวเอง:https/kvcache. ai/tools/kv-cache-calculator/
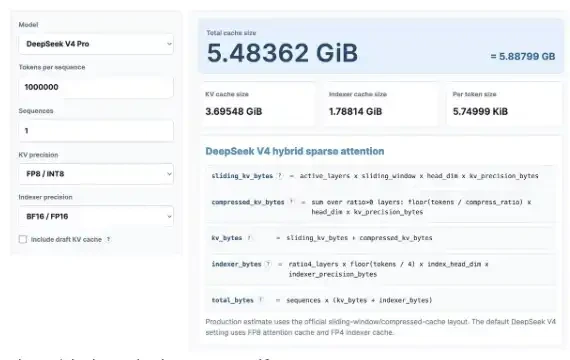
คุณสามารถเปิดเครื่องคิดเลขด้วยตัวเอง
น้อยกว่า 1 ล้านความยาวบริบท:
Deceg V4 ต้องการแค่ 5.48GB HBM
• GLM-5 ต้องการ 60GB HBM
QWend3-235B-A22B เรียกข้อมูล 89GB HBM。
หมายเหตุ:
ดีพฟีกเป็นโมเดล 1.6 ล้านล้านบาท
• GLM-5 มีพารามิเตอร์ประมาณ 70 พันล้านตัวแปร และ MLA และ DSA ของ ดีพซีก ที่ถูกใช้ แม้ว่ากลไกการได้ยินล่าสุดจะยังไม่ได้ใช้
• Qwen 3-235B-A22B มีตัวแปรประมาณ 23.5 พันล้านตัวแปร โดยใช้กลไกโฟกัส GQA。
ดีพเชคมีส่วนสําคัญในการลดความดันความทรงจํา ถ้า มี การ รับ เอา สิ่ง ประดิษฐ์ ใหม่ ๆ เหล่า นี้ ไป ใช้ อย่าง กว้าง ขวาง มัน ก็ จะ ลด ราคา ของ ตัว แทน ที่ ใช้ วัฏจักร ยาว เหยียด และ ปลดล็อค โปรแกรม ใหม่ ๆ。
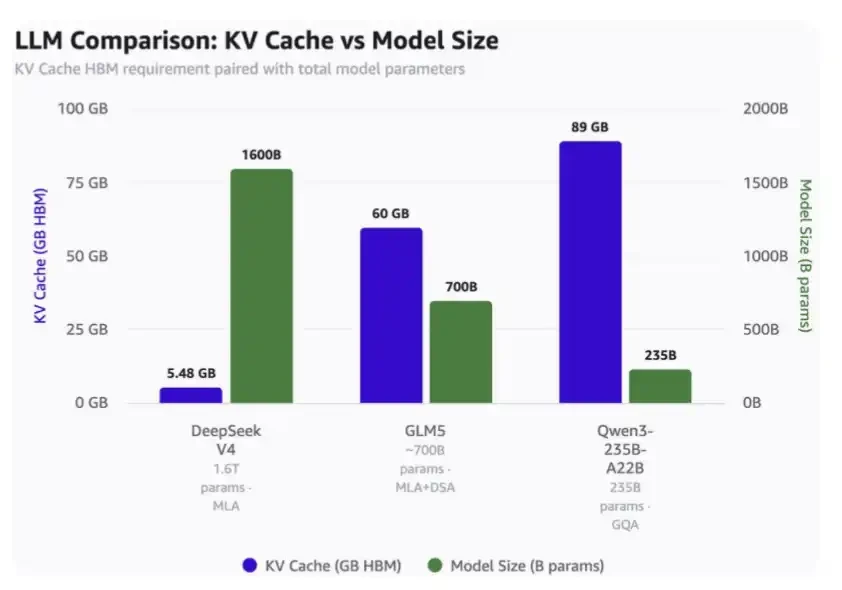
1 ล้านบริบท Togen เมื่อเทียบกับแคชของ KV ที่อยู่ในขนาดโมเดล
วิธีเบื้องหลังคําว่า "บ้า"
ขนาดแคชของ KV นั้นเล็กมาก โดยไม่ต้องเสียสละคุณภาพของโมเดล ดีพซีกจึงสามารถจัดหาแคชระยะยาวได้ ในราคาที่ต่ํามาก ราคาที่น้อยกว่า 3 เปอร์เซ็นต์ของโซเน็ต 4.6 แคช และดีพฟีกสามารถเก็บแคชได้หลายชั่วโมง。
สําหรับงานในวงยาว แคชของเควีที่มีขนาดเล็ก หมายถึงมันสามารถขนลง SMD ได้มากขึ้น โดย วิธี นี้ คุณ สามารถ ลด การ พึ่ง พา เอช บี เอ็ม ได้. จากมุมมองของอุตสาหกรรมฮาร์ดแวร์เอสไอของจีน HBM ไม่เพียงแค่เป็นอุปโภค บริโภคที่จํากัดเท่านั้น แต่ยังเป็นหนึ่งในความทรงจําที่หายากที่สุด。
นอก จาก นี้ ดีพ ซีก ได้ พัฒนา เทคโนโลยี ใน การ ขน แคช ของ KV จาก SSD ที่ เร็ว กว่า ดัง ที่ พรรณนา ไว้ ใน กระดาษ แผ่น เสียง ทาง เดิน ของ มัน。
การบีบอัดแคชของ KV แบบ December V4 นั้นมีขนาดใหญ่มาก จนขั้นตอนนี้อาจจะไม่จําเป็นเลยก็ได้。
แล้วใครเป็นผู้บริจาคโดยตรง ของการบีบข้อมูลแคชของ KV
ใครเป็นคนส่ง SSD? จําไว้, YMTC กําลังเติบโตเป็นยักษ์ในสาขา 3 มิติ NAND สามารถช่วย ดีพซีกหลีกเลี่ยงการนับคู่ KV ส่วน ดีป ซีก ได้ สร้าง ตลาด ขนาด ใหญ่ สําหรับ เอ็น ดี และ เอส ดี ไม่ เพียง สําหรับ คลัง สินค้า แยง เซ เท่า นั้น แต่ สําหรับ ผู้ ผลิต คน อื่น ๆ ด้วย。

แต่มันไม่ได้เกี่ยวกับ NAND และ SSD。
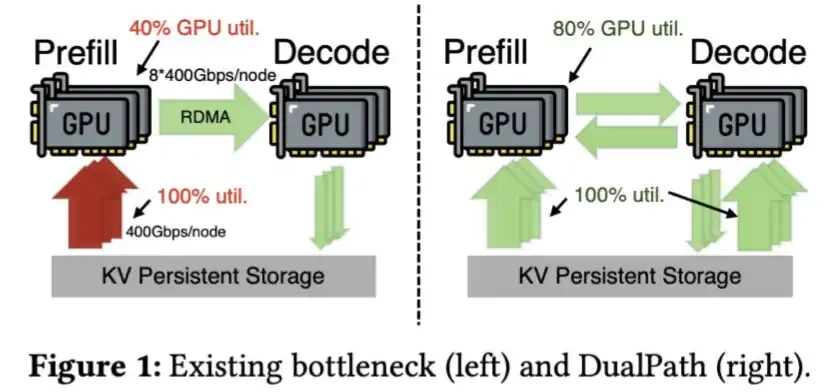
ความจําของ LPDDR ก็มีศักยภาพที่ดีเช่นกัน มันทําหน้าที่เป็นคลังน้ําหนักแบบจําลอง และโอนน้ําหนักเหล่านี้ไปที่ HBM ถ้าจําเป็น ดังนั้นการลดความดันใน HBM อุปสงค์ บล็อกที่ดีได้รับการตีพิมพ์โดยทีม SGLang แผนภูมิด้านล่างนี้แสดงให้เห็นว่าโปรแกรมทํางานอย่างไร。
ในขณะที่ดีพซีกไม่ได้ออกแบบเฉพาะสําหรับโปรแกรมนี้ สถาปัตยกรรมโมอี (MoE) ต้นแบบที่เชี่ยวชาญและน้ําหนัก 4 บิตของมัน ทําให้พื้นที่ลงจอดได้ง่ายขึ้น。
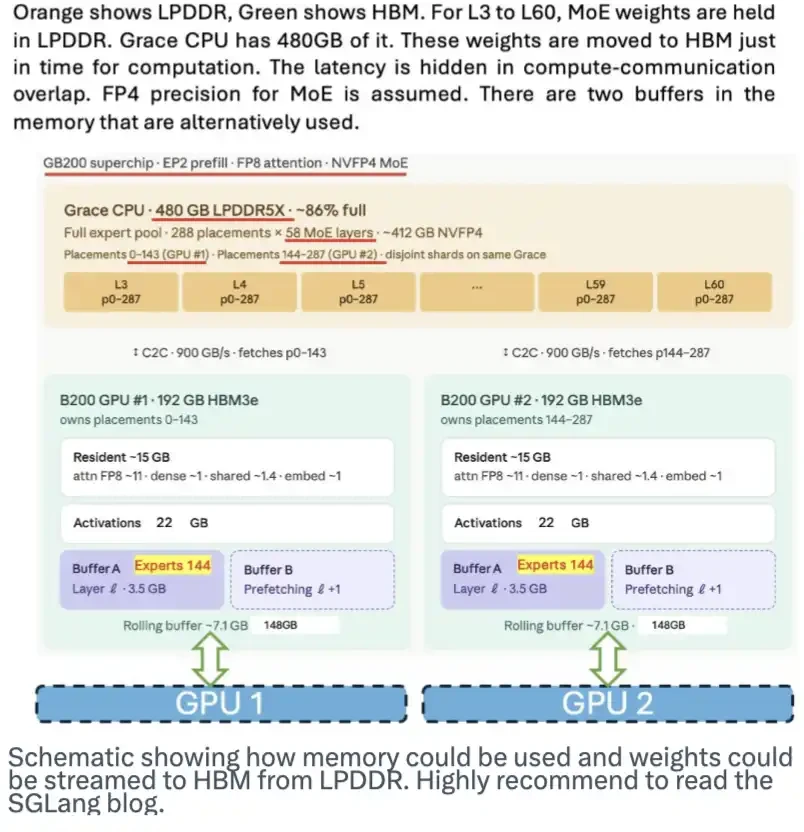
แผนภาพนี้แสดงวิธีใช้หน่วยความจํา และวิธีย้ายน้ําหนักแบบจําลองจาก LPDDR ไปยัง HBM 2554. โพสต์นี้เป็นส่วนหนึ่งของข่าวพิเศษของเรา Global Compress 2011。
นวัตกรรมนี้ เมื่อรวมกับแคช KV ที่ยังสมบูรณ์อยู่ จะลดความต้องการ HBM ได้อย่างมาก。
แล้ว ใครในประเทศจีน ผลิต LPDDR? คําตอบคือ CXMT ซึ่งเป็นที่เก็บระยะยาว พวกเขาเป็นเพียงครึ่งรุ่นหลังความเร็ว LPDDR และพวกเขาไม่ได้แตกต่างกันมากในความหนาแน่น。
นอก จาก ที่ มี มาก พอ แล้ว ระบบ นิเวศ ของ จีน AI ยัง มี สิ่ง ของ ต่าง ๆ มาก พอ อีก ใน อนาคต อัน ใกล้. นั่น ช่วย บรรเทา ความ กดดัน ไหม? คําตอบคือ ใช่ มองลงไป。

ใช้ ความ จํา ที่ ฉลาด เพื่อ ลด ความ ดัน ใน จี พี ยู / เอ ส ติก
การใช้ NAND เพื่อใช้เก็บแคชของ KV สามารถเข้าใจได้อย่างง่ายดาย: มันช่วยให้แคชของ KV คงตัวได้นานขึ้น, การลดความดันบน HBM ในขณะที่หลีกเลี่ยงการนับแคช KV เป็นสองเท่า ทําให้สามารถลดภาระการคํานวณบน GPU และ ASI ได้。
แล้ว LPDDR ทํางานในลักษณะเดียวกันไหม มันจะลดความดันการคํานวณได้อีกไหม นอกจาก ตําแหน่งที่เก็บน้ําหนักสามารถโอนไป HBM ได้
คําตอบคือ ใช่。
LPDDR สามารถใช้ในการจัดเก็บเนื้อหาจํานวนมากที่เรียกว่า Engram พวก เขา ชี้ ว่า โมอี สามารถ ขยาย ความ สามารถ ของ โมอี โดย การ คํานวณ สภาพ การณ์ แต่ ผู้ เปลี่ยน แปลง ไม่ มี กลไก “ค้นหา ความ รู้ ” แบบ ดั้งเดิม. ด้วย เหตุ นี้ ผู้ แปลง จึง มัก ต้อง จําลอง กระบวนการ ค้นคว้า ด้วย วิธี ที่ ไม่ มี ประสิทธิภาพ โดย การ คํานวณ。
เพื่อ จะ แก้ ปัญหา นี้ ได้ ดีด เลิช เสนอ โมดูล Engram. มันปรับความทันสมัยของ N-gram คลาสสิกการฝังตัวเป็น O-(1) กลไกการค้นหาตามพื้นฐานของฮาชิ สร้างเส้นทางที่เสริมสร้างและชลประทาน。
วิธีการคํานวณการออมนี้ แต่ยังต้องใช้ความทรงจําในการขนโต๊ะฝังศพ ซึ่งสามารถมีขนาดใหญ่มากในตัวมันเอง。
พูดง่ายๆก็คือ มันเป็นสูตรการเปลี่ยนความทรงจําทั่วไป แต่ประเด็นสําคัญคือ ในแง่ของค่าใช้จ่ายในการอ่านข้อมูลแต่ละบิต ด้านของหน่วยความจํานี้ถูกกว่ามาก ดัง นั้น ใน ขอบ เขต ใหญ่ ๆ นี้ จึง เป็น การ แลก เปลี่ยน ที่ เป็น ประโยชน์ มาก。
นั่นคือวิธีที่ดีพฟีกคํานวณเงินออม โดยการเสียสละส่วนหนึ่งของหน่วยความจําของเขา。
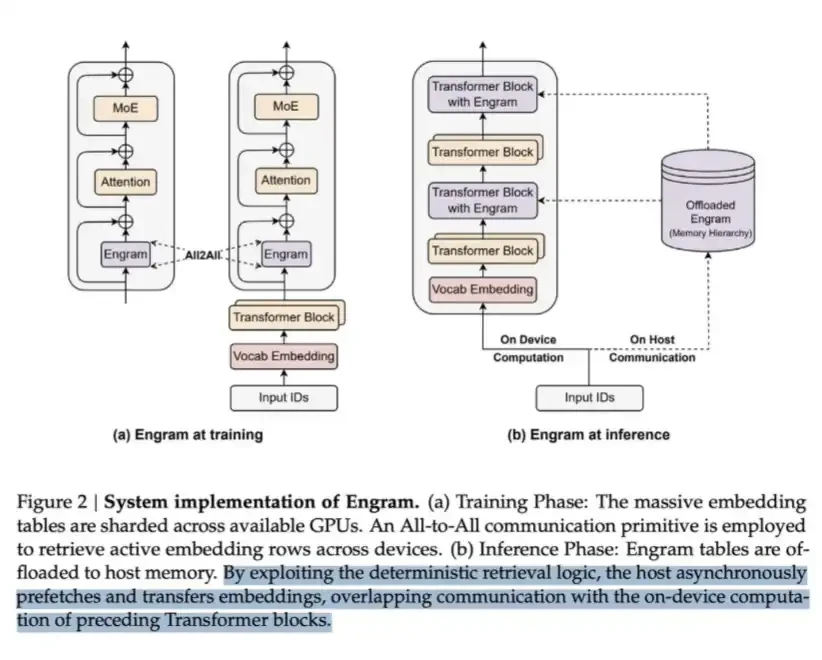
เป็นทางเลือกที่คุ้มค่า
หาก ปราศจาก ความ หนา แน่น ของ ผลึก และ EUV ใน ระดับ เดียว กัน อัลกอริทึม เอฟ พี ยู และ แอ ส ติก ของ จีน ก็ คง จะ อยู่ ห่าง ไกล จาก จี พี พี ยู ตะวัน ตก ใน อัลกอริทึม เอฟ แอล โอ เอส เดิม ของ ตน. นอก จาก นั้น ยัง มี ช่อง ว่าง สําคัญ ใน การ ประทับ ตรา ขั้น สูง. การค้าดังกล่าวจึงคุ้มค่าสูงมาก โดยเฉพาะถ้าประเทศจีนสามารถผลิตหน่วยความจํา NDD และ LPDR ในปริมาณขนาดใหญ่。
นึกถึงกลยุทธ์ระยะยาวของดีพซีก
จากนวัตกรรมเหล่านี้ ดีพซีคไม่ได้มุ่งหวังกําไรหลายร้อยล้านดอลลาร์ หลายตัวเลือกที่มันได้ทําในอดีต แสดงถึงสิ่งนี้ ถึงตอนนี้ ไม่มีความหลากหลาย ไม่มีโมเดลเสียง。
มันเกี่ยวข้องกับเกมในระยะยาวของผู้ป่วย ที่สามารถเพิ่มเงินได้ถึง 10 ล้านล้านดอลลาร์。
นี่ไม่ได้เป็นเพียงเพื่อทําให้ผู้ผลิตภายในประเทศจีน เป็นผู้เล่นหลักในประเทศจีน และแม้กระทั่งในตลาดฮาร์ดแวร์เอไอทั่วโลก แต่ยังเป็นการลดความต้องการด้านทรัพยากรและทําให้การอบรมและบริการ AI ของ AI ผล ก็ คือ จี พี ยู, แอ ส ติก, และ ผู้ ผลิต ชิป เครือ ข่าย หลาย คน มี โอกาส ที่ จะ เป็น ทาง เลือก ที่ มี ประโยชน์。
ในเวลาเดียวกัน นวัตกรรมเหล่านี้ จะเป็นประโยชน์ต่อระบบนิเวศแบบโอเพนซอร์สของตะวันตก และผู้ผลิตฮาร์ดแวร์รุ่นใหม่。
สัญญาณทั้งหมดได้ปรากฏขึ้นจริง ลองมาทบทวนรายละเอียด นวัตกรรมที่ ดีพซีค ได้เสนอมา
รุ่นผสมแบบ (ME) และ MLA นํามาใช้ใน ดีพซีก V2
ดีพซีกแนะนํา โมเอะ และ เอ็มแอลเอ ใน V2 โมอี ลด ปริมาณ การ คํานวณ ที่ จําเป็น ใน การ ฝึก รุ่น ที่ มี การ ใช้ ปืน ใหญ่ สูง โดย ประมาณ 40 ถึง 50 เปอร์เซ็นต์; เอ็ม แอล เอ ลด แคช เค วี ลง 90 เปอร์เซ็นต์。
นี่ทําให้มันมีประสิทธิภาพพอ ที่จะรื้อแคชของ KV บน SSD。
2024 แนวความคิดเหล่านี้ได้รับการตีพิมพ์ครั้งแรกโดย ดีพซีก ในปี ค.ศ. ต่อ มา พวก เขา ยัง ได้ วาง พื้น ฐาน สําหรับ การ ฝึก อบรม ที่ ดีพ ซีก V3 ด้วย. ในขณะนั้น ดีพซีกได้ฝึกระบบที่มีผลงานใกล้เคียงกับระดับรุ่นปิด โดยใช้แค่ H800 GPUs ที่อ่อนแอกว่า。
2. ดีเอสเอ: แนะนําใน ดีพซีก V3. เพื่อลดค่าใช้จ่ายในการคํานวณ ภายใต้สถานการณ์ที่ยาวนาน ในขณะที่ลดความดัน HBM bandwidth。
บทบาทหลักของ DSA คือเพื่อให้แน่ใจว่าปริมาตรที่คํานวณไม่ได้เพิ่มขึ้นตามความยาวของบริบท แผนภูมิด้านล่างนี้แสดงว่าเวลาประมวลผลสําหรับ ดีพซีก-V3.2 ส่วนใหญ่คงที่เมื่อความยาวของบริบทเพิ่มขึ้น。
3 MHC: ดีพซีกนําเสนอในเดือนธันวาคม 2025 ในหนังสือพิมพ์ MHC: Maniscover-Concogricster-connects。
mHC เป็นนวัตกรรมที่ระดับเมโคร-โครงสร้างของ ดีพซีก ออกแบบการไหลข้อมูลระหว่างชั้นหม้อแปลง。
ในอดีต เนื่องจากรีเน็ต โมเดลมักจะใช้ การเชื่อมต่อมาตรฐาน เช่น x + F(x). ในทางตรงกันข้าม เอ็มเอชซี ได้ขยายกระแสเสียงให้กว้างขึ้น เป็นช่องข้อมูลที่คล้ายคลึงกันหลายช่อง ประเด็นคือมันเชื่อมเมทริกซ์ลูกผสม เข้ากับเมทริกซ์การแบ่งตัวคู่ นั่นก็คือ จํากัดมันกับเบิร์กกอฟ โพลีเฮดรัส ผ่านการฉายแบบ Sinkhorn-Knop วิธี นี้ คือ โดย ทาง คณิตศาสตร์ ระยะ ของ สัญญาณ คงที่ ไม่ ว่า แบบ จําลอง จะ ซ้อน กัน ลึก แค่ ไหน。
นี่พูดถึงความไม่มั่นคงอย่างร้ายแรง ที่เคยประสบมาโดย ไฮเปอร์คอมเพล็กซ์ hyper-Connects นําเสนอครั้งแรกโดย by byte แต่ปราศจากการยับยั้งสัญญาณที่ส่งโดย สมัชชาทั่วไปถึง 3000 เท่าของขนาด พารามิเตอร์ 27 พันล้าน。
ค่า ใช้ จ่าย ใน การ คํานวณ ของ เอ็ม เอช ซี ต่ํา มาก: ต้อง เสีย ค่า ใช้ จ่าย ประมาณ 6.7 เปอร์เซ็นต์ ของ เวลา ฝึก อบรม จริง ๆ เพราะ ไม่ ได้ เปลี่ยน ชั้น ความ สนใจ หรือ ชั้น เอฟ แอล เอ็น ของ FLOPS แต่ ก็ เพียง แต่ เปลี่ยน โหมด การ ออก แบบ ชั้น ต่าง ๆ ระหว่าง ชั้น ต่าง ๆ เหล่า นี้。
อย่างไรก็ตาม ประสิทธิภาพที่เพิ่มขึ้นที่นํามาค่อนข้างมีความสําคัญ: ในขนาด 27 พันล้านตัวแปร mHC เพิ่มขึ้น 7.2 จุด ในงานหาเหตุผลขนาดใหญ่ 3.2 จุดบน JOP 2.8 จุดบนงานทางคณิตศาสตร์ของ GSM8K และ 1.4 จุดในงาน mMLU ความรู้ทั่วไป การ เพิ่ม เหล่า นี้ ประสบ ผล ภาย ใต้ ขนาด แบบ จําลอง เดียว กัน และ งบ การ คํานวณ แทบ จะ เหมือน กัน。
โดยหลักแล้ว เอ็มเอชซี ประสบความสําเร็จในหน่วยข้อมูลที่สูงขึ้น โดยการขยายเส้นทางของข้อมูล。
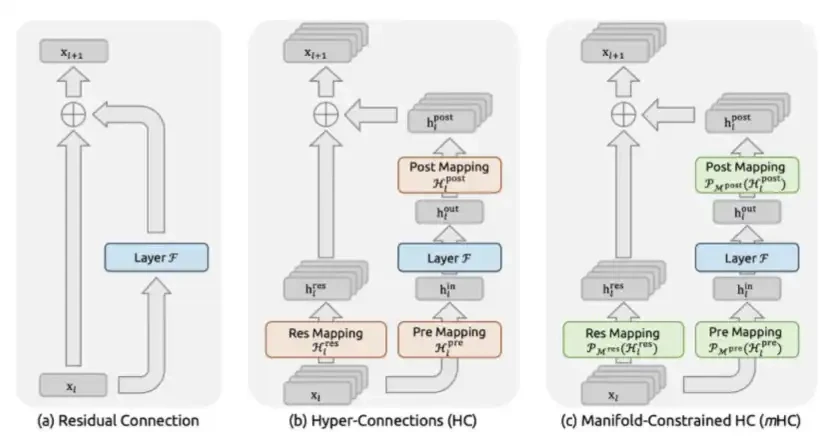
mHC เป็นการออกแบบสถาปัตยกรรมที่ซับซ้อน แต่สามารถนําไปสู่กระบวนการฝึกที่เสถียรมากขึ้น และหน่วยสืบราชการลับสูง。
CSA, HSA: ดีพซีกถูกนํามาใช้ใน V4 เมื่อ April 2026。
CSA และ HSA มีจุดมุ่งหมายที่จะลดความต้องการแคชของ KV โดยเพิ่ม 90% โดยบีบ KV Tokeen ขณะเดียวกันลดปริมาณของ FLOS ที่ต้องการลงอย่างมาก ดังนั้นการลดความดัน HBM และ GPU / ASAIC。
5- Engram: ดีพซีกถูกนํามาใช้ในไตรมาสแรกของ 2026 โดยหลักแล้วใช้หน่วยความจํา, เช่น LPDR เพื่อแลกเปลี่ยนกับประสิทธิภาพการคํานวณ。
ดัง ที่ แสดง ให้ เห็น ใน แผนภูมิ ราย ละเอียด ข้าง ล่าง นี้ ขณะ ที่ งบ ประมาณ โดย รวม ทั้ง หมด ก็ เหมือน กัน เอนแกรม ได้ ทํา ให้ เกิด การ ปรับ ปรุง ความ สําเร็จ ที่ สําคัญ。
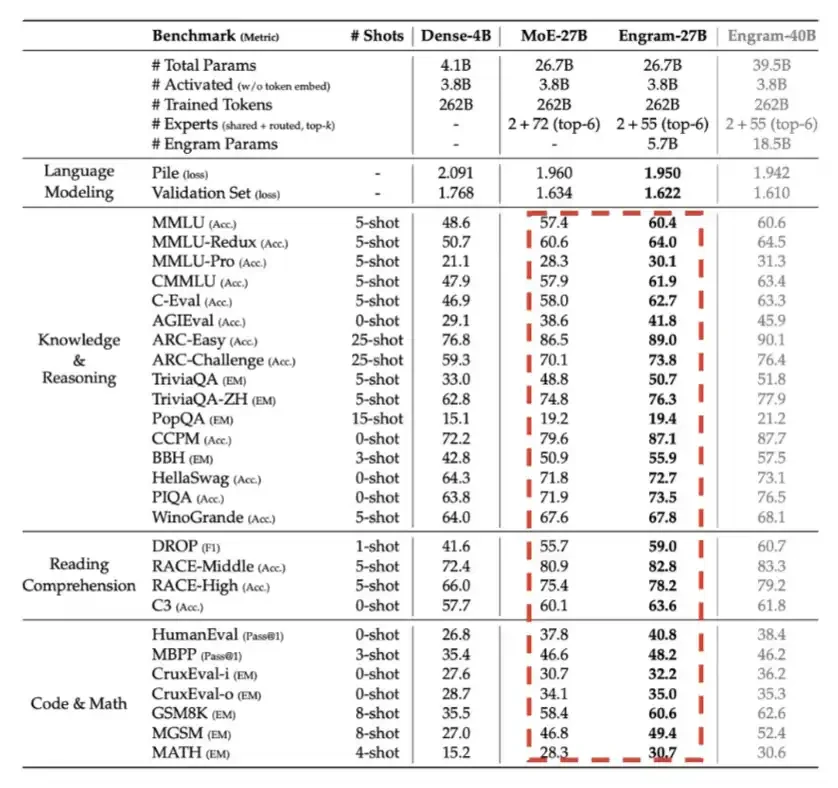
6 Engram: ดีพซีกถูกนํามาใช้ในไตรมาสแรกของปี 2026 โดยหลักแล้วใช้หน่วยความจํา, I.E. LPDDR เพื่อแลกเปลี่ยนกับประสิทธิภาพการคํานวณ。
ดัง ที่ แสดง ให้ เห็น ใน แผนภูมิ ราย ละเอียด ข้าง ล่าง นี้ ขณะ ที่ งบ ประมาณ โดย รวม ทั้ง หมด ก็ เหมือน กัน เอนแกรม ได้ ทํา ให้ เกิด การ ปรับ ปรุง ความ สําเร็จ ที่ สําคัญ。

นี่คือข้อเสนอของดีพซีก ที่จะแบ่งปันกับผู้ผลิตฮาร์ดแวร์ในกระดาษ V4 ฉันมั่นใจว่าพวกเขาจะให้ผลตอบรับเพิ่มเติม ในการสื่อสารออนไลน์。
7 การ นํา เข้า ไป สู่ จุด ลาด ลาด ตระเวน ใน ทิศ ทาง เดียว กัน: ดีพ ซีก ไม่ เพียง แต่ พูด ถึง คอ ขวด คณิตศาสตร์ ของ เขา เอง เท่า นั้น แต่ กําลัง ขับ ขี่ ระบบ นิเวศ ของ จีน เพื่อ แข่งขัน กับ ระบบ นิเวศ แบบ ตะวัน ตก。
ด้วยความช่วยเหลือของ capillaryLang นักพัฒนาสามารถเตรียมเคอร์เนลได้เพียงครั้งเดียว เช่น รหัสย่อยที่ใช้คํานวณ และทําให้มันทํางานได้สําเร็จบนแพลตฟอร์มฮาร์ดแวร์หลายระบบ หากมีการรองรับแบ็คเอนต์Lang ที่สอดคล้องกัน。
ฉันหวังว่าห้องไอไอเออื่น ๆ จีนจะเข้าร่วม นี่จะช่วยผู้ผลิตฮาร์ดแวร์ชาวจีน ให้จัดการทางอ้อม กับสิ่งที่เรียกว่า คูเมือง CUDA ในเวลาเดียวกัน มันจะปล่อย ฮาร์ดแวร์แบบตะวันตกมากขึ้น เช่น AMD。
ควรสังเกตไว้ว่า แพลตฟอร์มฮาร์ดแวร์ของจีน SI ที่มีอยู่แล้วทําให้ CUDA สามารถเข้ากันได้ หรือระบบแปลแบบ CUDA ตัว อย่าง เช่น หอย มัส เซิล, หอย มัส เซิล, ฝา ผนัง และ แกน กลาง ของ แต่ ละ วัน เป็น ผู้ ผลิต ชิป ชาว จีน ที่ มี ความ สามารถ ใน การ ทํา งาน ของ ซี ยู เอ ดี เอ สูง ผ่าน ชั้น ทราน สเล ชัน. ตามหลักทฤษฎีแล้ว พวกเขาไม่จําเป็นต้องใช้ เส้นรุ้ง。

เพิ่มระดับการเรียนรู้และโปรโตเซลล์ขนาดใหญ่
เมื่อดีพซีคได้แหล่งที่มาของแคลคูลัสเพิ่มขึ้น เช่น ฮาร์ดแวร์ที่มีมากขึ้น และต้นแบบเองก็ลดความต้องการทรัพยากรการคํานวณ。
การ เรียน รู้ เพิ่ม เติม เรียก ร้อง การ เรียน รู้ รุ่น ต่าง ๆ มาก มาย ซึ่ง ก็ คือ สัญลักษณ์ นับ ล้าน. ใน ไม่ ช้า กระบวนการ นี้ จะ แพง เหลือ เกิน. ยิ่ง กว่า นั้น ถ้า จําเป็น ต้อง ฝึก ใช้ ความ ยาว 1 ล้าน เส้น ทาง ที่ ยาว เท่า กัน. มีเพียงโมเดลการฝึกในวิถีโคจรแบบซุปเปอร์ลองนี้เท่านั้น ที่จะสามารถรองรับภารกิจจักรยานยาวได้อย่างแท้จริง。
นอก จาก นี้ เมื่อ มี ทาง เลือก ต่าง ๆ ใน การ ใช้ อุปกรณ์ เพิ่ม ขึ้น ดีพ ซีก ก็ จะ มี ทรัพยากร ต่าง ๆ มาก ขึ้น ซึ่ง จะ ทํา ให้ การ ค้นคว้า ง่าย ขึ้น โดย ใช้ เครื่อง มือ. CRL อ้างถึง AI ออกแบบและดําเนินการทดลองของตัวเอง วิธี การ เช่น นั้น จะ เกี่ยว ข้อง กับ ความ ผิด พลาด ใน การ ทดสอบ มาก มาย และ ค่า ใช้ จ่าย ที่ เพิ่ม ขึ้น อย่าง รวด เร็ว. แต่ การ ทํา งาน ของ อาร์ เอ ส ไอ เป็น สิ่ง จําเป็น เพื่อ การ สํารวจ อวกาศ แบบ จําลอง ที่ สมบูรณ์ แบบ. ดีพซีคต้องมีความสามารถในการผ่าตัดก่อนจะไปเอจีไอหรือหลังจากนั้น ASI。
ดีพซีค สิ่งที่เราทําวันนี้ อุตสาหกรรมทั้งหมดจะติดตามในวันพรุ่งนี้ ไปกันเถอะ
ดีพซีกนวัตกรรม ในทิศทางของโมเดลลูกผสมผู้เชี่ยวชาญ เอ็มแอลเอ, ดีเอสเอ ฯลฯ ได้ถูกนํามาใช้ในห้องปฏิบัติการเอไออื่น ๆ ทั่วโลกและในประเทศจีน。
ยกตัวอย่างเช่น นักพัฒนาซีรีส์ GLM ZAI ใช้ MLA และ DSA คิมิ หรือ มูน ช็อตต์ ก็ ใช้ เอ็ม แอล เอ เช่น กัน และ ไม่ เคย กล่าว อย่าง ขะมักเขม้น ว่า โครง สร้าง ของ มัน อาศัย สถาปัตยกรรม ดีป ซี สก์. ส่วนดีพซีกใช้มูออน โอปมิมิเซอร์ ซึ่งใช้ครั้งแรกในการฝึกขนาดใหญ่โดย คิมิ (มูนช็อตต์)。
ควร สังเกต ว่า:
MOE ถูกเสนอครั้งแรกโดย Google ในปี ค.ศ. การบริจาคของดีพฟีก คือการใช้โมอีในปริมาณที่มาก และคิดค้นทักษะของมัน。
Muon, The moperum Outhogoalized by Newton-Schulz Oppimcier, นําเสนอโดย เคลเลอร์ จอร์แดน นักวิจัยด้านการเรียนรู้ของเครื่อง เมื่อปลายปี ค.ศ. ทีม คิมิ (มูนช็อต) เป็นทีมแรกที่ใช้ในการฝึกขนาดใหญ่。
แล้วการทําเงินล่ะ
เราสามารถมอง OpenAI เป็นตัวอย่างที่น่าสนใจ。
OpenAI ได้รางวัล AMD และเซเรบราส แชร์ โฮลด์/ยูไนเต็ด จากราคาที่ต่ํากว่า ซึ่งเกี่ยวข้องกับการบริโภคของแคลคูลัส สําหรับ AMD and Crebras นี้เป็นข้อตกลงที่กําไรมาก เพราะเมื่อ OpenAI มุ่งมั่นที่จะใช้ฮาร์ดแวร์ของพวกเขา ความเป็นไปได้ของความสําเร็จในระยะยาวของพวกเขาเพิ่มขึ้นอย่างมาก。
กระสุน AMD บรรจุ คํา แถลง ดัง นี้:
“ เพื่อ เป็น ส่วน หนึ่ง ของ ข้อ ตก ลง นี้ และ เพื่อ จะ ทํา ให้ ผล ประโยชน์ ทาง ยุทธศาสตร์ ของ ทั้ง สอง ฝ่าย ประสาน ลง รอย กัน มาก ขึ้น เอ เอ็ม ดี จึง ได้ ออก ใบ รับรอง การ เป็น เจ้าของ หุ้น มาก กว่า 160 ล้าน หุ้น ส่วน ของ AMD สามัญ ซึ่ง ที ละ เล็ก ที ละ เล็ก ที ละ น้อย ตาม ความ สําเร็จ ของ เหตุ การณ์ เฉพาะ อย่าง หนึ่ง. ส่วน แรก จะ ได้ รับ การ ออก แบบ เมื่อ ทํา การ บังคับ ใช้ ครั้ง แรก ใน ขณะ ที่ ชุด ต่อ ๆ ไป จะ ได้ รับ การ ออก แบบ ที ละ เล็ก ที ละ น้อย ขณะ ที่ มาตรา การ จัด หา ขยาย เป็น 6 กิวา. สภาวะการแบ่งชนชั้นยังเชื่อมโยงเข้ากับความสําเร็จของ AMD ของความเสมอภาคของเป้าหมายราคาเฉพาะ และความสําเร็จของ OpenAI ของเทคนิคและเชิงพาณิชย์

ผมคาดหวังว่า ดีพ ซีค จะเข้าอยู่ในข้อตกลงที่คล้ายกัน ด้วยการทํางานอย่างลึกซึ้ง กับบ้านหลายหลัง。
เนื่องจากชาวตะวันตกทั้งหมด รวมถึงพันธมิตรเอเชียตะวันออก มีมูลค่าทางการตลาดทั้งหมด มากกว่า 10 ล้านล้านบาทในปัญญาประดิษฐ์。
นี่ ไม่ เพียง แต่ ทํา ให้ ดีพ ซีก มี ราย ได้ จาก ธุรกิจ ที่ ไม่ มี การ นํา มา ใช้ ตาม ประเพณี เท่า นั้น แต่ ยัง ทํา ให้ สิ่ง ที่ เขา เรียก ว่า เป้า หมาย ใน การ ทํา ให้ AGI เป็น ประโยชน์ แก่ ทุก คน ด้วย. ลียง เวนไซเป็นแฟนตัวยงของ จิม ไซมอนส์ และนักเล่นทุนที่ฉลาดพอ และเขาพลาดไม่ได้。
ถ้าคุณมองย้อนกลับไปว่า ดีพซีคทําอะไรไปบ้าง นั่นคือคําอธิบายเดียวที่สมเหตุสมผล。
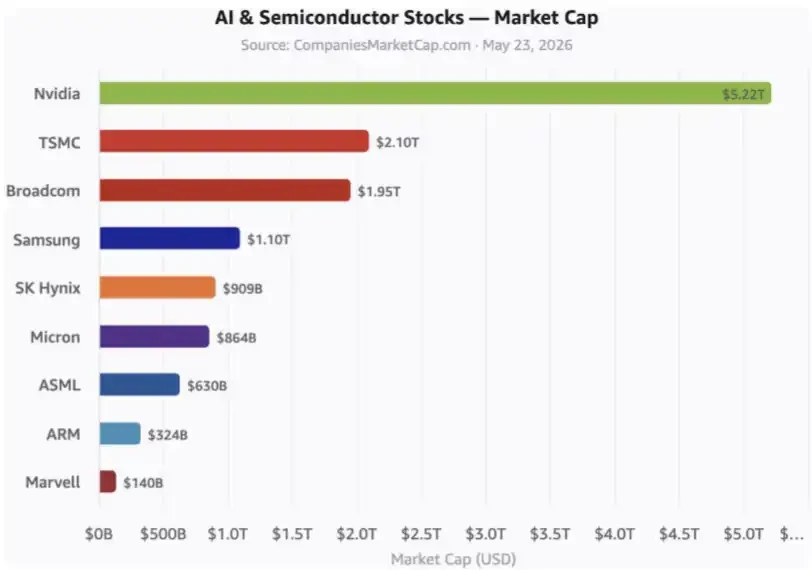
นี่คือหลักหุ้น AI ตัวตัวเลขไม่ได้รวมค่าไฮเปอร์ส, เช่น ผู้ผลิตเมฆขนาดใหญ่ และบริษัทอื่น ๆ อีกมากมาย。
