
DeepSeek의 억억 경로 : 오픈 소스와 하드웨어 생태의 조개
더 많은 국내 스토리지, 칩 및 네트워크 제조업체를 AI 인프라로 활용하여 훈련 및 임계 값을 낮추기

원본 제목 : DeepSeek의 10 추적 USD 그랜드 전략
에 의해 원래: @bookworkmengr
Original by Peggy, 블록 비트
편집자 압박: 지난해 동안 DeepSeek의 토론은 모델 성능, 오픈 소스 전략 및 가격 전쟁에 주로 초점을 맞추고 있습니다. 그러나 DeepSeek를 이해하는 유일한 방법은 "판매 또는 구독하지 않는" "당신은 모델" "당신은 할 수?"。
이 문서는 더 급진적인 판단을 선물합니다: DeepSeek 's 목표는 신청 층을 통해서 반드시 단기적인 현실화가 아닙니다, 그러나 Reshape AI 's 훈련의 비용 구조 및 일련의 밑바닥 위로 구조상 혁신을 통해 이유 및 간접적으로 새로운 기계설비 생태 대형을 승진시키기 위하여. MoE에서, MLA, DSA, CSA, mHC, Engram, Dual Path 및 TileLang에, DeepSeek의 기술 경로는 중앙 문제점의 주위에 구조화되었습니다: HBM, 고급 프로그래밍, 포함 및 CUDA 생태가 제한될 때 더 강한 모델을 실행하는 방법。
이 문서의 가장 흥미로운 것은 DeepSeek가 API 또는 구독에서 수백만 달러를 벌 수 있는지 여부는 아니지만 모델 기능, 메모리 시스템 및 국가 하드웨어의 생태를 연결하는 것이 여부입니다. 모형: KV Cache 압축은 HBM, NAND 및 SSD에서 신뢰성을 감소시킵니다. 장기 캐시를 수행 할 수 있으며 LPDDR은 무거운 흐름 하중 및 Engram 저장 및 TileLang은 CUDA 모트를 약화시킵니다. 이러한 혁신이 계속 확산을 계속하면, beneficiaries는 DeepSeek 자체뿐만 아니라 저장, ASIC, GPU, 웹 칩 및 전체 AI 인프라 체인이 아닙니다。
물론, "산업 생태학 10 조 달러"에 대한 텍스트의 판단은 여전히 더 극적인 톤을 수행 "1 조 달러"입니다. 그러나 DeepSeek를 이해하는 중요한 경로를 제공합니다 : 오픈 소스는 반드시 상업화를 포기하지 않으며, 저렴한 가격은 반드시 단순히 시장을 빼앗지 않습니다. DeepSeek를 위해, 진짜 사업은 신청 수준에 있을지도 모릅니다, 그러나 더 기계설비가 유효할 것을 돕고 더 낮은 비용 AI를 공급하기 위하여 그것을 가능하게 합니다. 다른 말에서, 그것은 반드시 모델 자체를 판매하지 않습니다, 그러나 AI 인프라의 차세대의 가능성。
다음은 원본 텍스트입니다:

DeepSeek가 돈을 벌고 많은 돈을 벌 수있는 방법에 대해 생각하십니까
그것은 GLM, MoonShot 및 MiniMax와 같은 경쟁력있는 프로그래밍 구독을 소개하지 않습니다. 또는 다관식, 오디오, 비디오 모델이 있습니다. 지금까지 자체 하네스를 가지고 있지 않습니다. 모델 통화, 도구 액세스 및 작업 실행을위한 외부 운영 프레임 워크 -- 그들은 최근 관련 게시물을 모집하기 시작하지만, 그들은이 시스템을 구축 준비하고있다。
동시에 DeepSeek는 오픈 소스의 측면에 오랫동안 확고한 것 같습니다. "secrets"를 공개적으로 공유 할 것입니다. 그게 다요? 아무것도에 대 한 돈을 점화 하지? 10 억 달러를 투자하려고하는 투자자는 하수인으로 돈을 던지고 있습니까
개인적으로, 나는 대답은 반대이다。
다음, 나는 DeepSeek가 지금까지 수행 한 것을 기반으로 한 일부 관측을 만들고 다음과 같습니다. DeepSeek CEO의 목표는 현재 모델 경쟁보다 훨씬 더 많은 것입니다. 그는 더 큰 상을 목표로했다 : DeepSeek는 $ 10 조의 새로운 산업을 운전하면서 $ 1 조의 valuation을 명중 할 수있는 기회가있었습니다。

DeepSeek의 최신 라운드에서 TechInAsia
Revisit DeepSeek의 "노래 여행"
DeepSeek는 바람에 대해 실행되었습니다. 그것은 약간 더 강한 모델을 압연하고 그 후에 프로그래밍 구독과 같은 직접적인 현실화 응용 프로그램으로 포장하는 것을 선택하지 않았다. 1 월 27, 2025, 나는 DeepSeek의 "hero trip"에 대해 널리 순환 트윗을 보냈습니다. 오늘, 이야기는 더 재미가된다。
다른 사람들은 여전히 집중 모델을 구축하려고하는 동안 DeepSeek는 더 어려운 전문 하이브리드 모델을 선택했습니다 ( Express, MoE의 Mixture)。
"FIRST PRINCIPLE" 메소드를 사용하여 새로운 GRPO 알고리즘을 발명하여 주류를 대체하지만 비용이 많이 드는 PPO는 학습 알고리즘을 강화했습니다。
검증된 Renewals, RLVR의 보강 학습 (Reinforcement Learning from Verified Renewals, RLVR)은 모델 소모를 위한 핵심 전략입니다。
또한 Multi Token Forecast를 통해 간단한 surmise 디코더링 전략을 제안했습니다. 또한 훈련 신호를 더 집중시키는 동시에。
그들은 제한된 GPU 자원의 효율성을 향상시키기 위해 Zero Bubble 라인을 완벽하게했습니다。
그들은 MoE 모델을 배포하기 위해 쉽게 만들 수있는 전문가의 로드 밸런서를 발표했다. 특히, "Wide Extrat Parallel"전략을 통해 모델은 더 큰 시계와 함께 제공 할 수 있습니다。
그들은 MLA, DSA, CSA, HCA와 같은 메커니즘을 발명하여 KV Cache 's 수요를 줄이고 상황에 따라 증가 된 컴퓨팅 수요로 지속적으로 유지해야합니다。
그들은 컴퓨팅 효율성을 위해 메모리 교환에 Engram을 발명했다。
또한 mHC를 발명하여 모델 확장을 계속할 수 있는 안정화 훈련을 가능하게 합니다. 많은 유사한 예제가 있습니다。
"heroes'travel"의 가장 일반적인 narrative 구조에서 영웅은 여행을 리드하는 아웃셋에서 결코 결정하지 않습니다. 그는 자신의 진정한 위대한 임무를 발견하고 많은 장애물을 수행하기 위해 여행의 과정을 통해 학습하고있다. 그는 많은 의심의 여지가 있지만, 그는 그들을 무시하기로 선택합니다. 그는 또한 많은 악의적 인 행위자를 만날 것입니다. 그는 명백한 결함 또는 질화, 그러나 궁극적으로 그들을 극복하고 그의 임무를 성취했다. 눈에 띄는 도전과 함께 직면, 그는 얼라이언스를 형성하고 스카이스와 귀중한 리소스를 사용하는 방법을 배우는 방법을 찾을 수 있었다. 그것은 관객이 영웅을 응원하는 것입니다. DeepSeek가 추종자, 글로벌 존경 및 야당을 수상한 이유입니다。
나는 세부 사항에 설명 할 때 DeepSeek는 오랫동안 도로에 있었고 점차 궁극적 인 운명을 발견했다 : 그 목표는 프로그래밍 구독을 판매하지 않지만, 10 조 달러 중국 AI 하드웨어 생태를 홍보하고 $ 1 조의 자체 valuation을 달성 할 수 없습니다. 공정에서, 그것은 또한 서양 하드웨어 생태의 많은 새로운 entrants에 대한 기회를 만들 것입니다。

몇 가지 흥미로운 KV 캐시 계산 시작
@SemiAnalysis 최신 정보:
DeepSeek는이 문제를 누군가보다 잘 해결했습니다
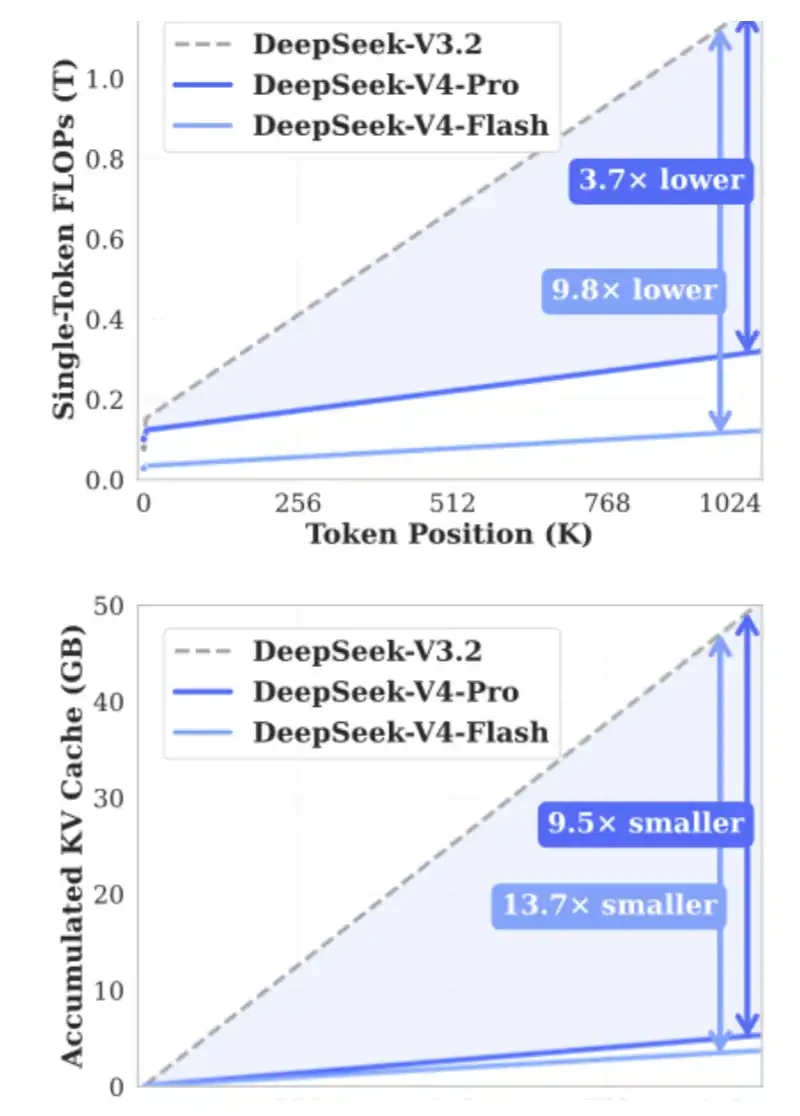
흥미로운 KV 캐시 계산으로 시작합시다. 걱정하지 마세요. 우리는 최근 출시 된 KV 캐시 계산기를 사용하여 KV 캐시가 DeepSeek V4 Pro로 가져올 수 있으며 최신 GLM 및 Qwen 모델과 비교합니다。
여기에 1 백만 개의 컨텍스트 길이로 계산합니다. KV는 8 비트이며 인덱서는 16 비트입니다. 이 계산기를 직접 시도 할 수 있습니다 :https://kvcache.ai/tools/kv-cache-calculator/
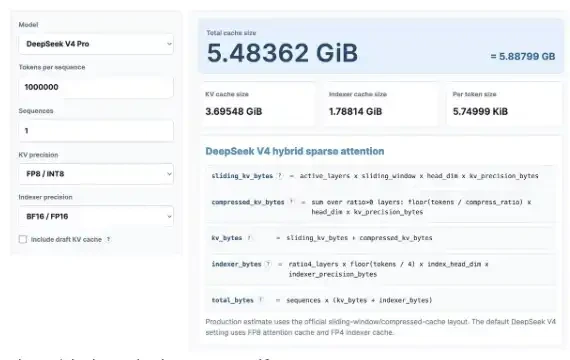
계산기를 직접 켤 수 있습니다
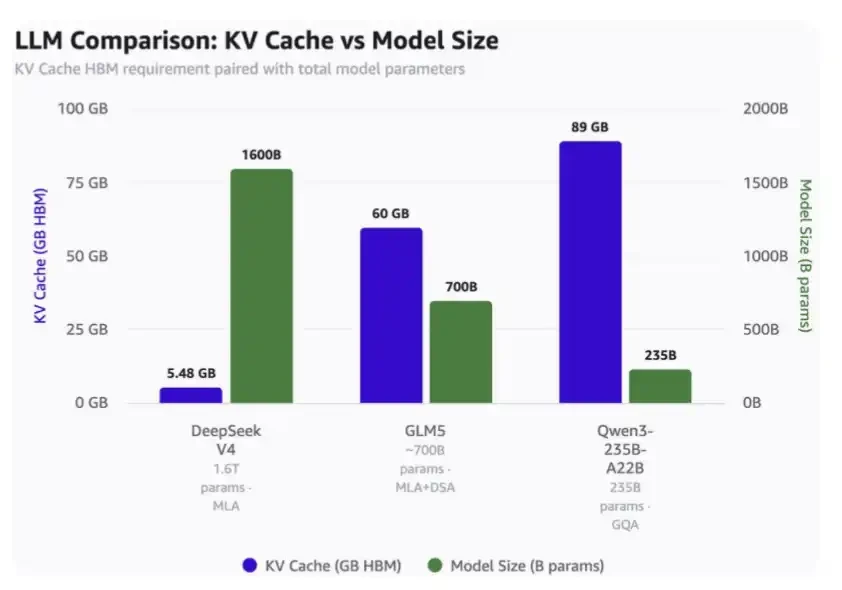
1백만개의 맥락 길이의 밑에:
DeepSeek V4는 단지 5.48GB HBM를 요구합니다
• GLM-5는 60GB HBM를 필요로 합니다
Qwen3-235B-A22B는 89GB HBM까지 요구합니다。
참고 :
DeepSeek는 1.6 조억 모수 모형입니다
• GLM-5는 약 70 억 매개 변수 및 MLA 및 DeepSeek의 DSA가 사용되었지만 최신 응축주의 메커니즘이 사용되지 않았습니다
• Qwen 3-235B-A22B는 GQA 초점 기계장치를 사용하여 대략 23.5 억 모수입니다。
DeepSeek는 메모리 압력을 줄이기위한 기본 기여를했습니다. 이러한 혁신이 널리 채택되면, 그들은 크게 긴 사이클 에이전트의 실행 비용을 줄이고 새로운 응용 프로그램의 다음 세트를 잠금 해제합니다。
1백만개의 토큰 컨텍스트 versus KV Cache 모형 가늠자에 점유
"crazy" 뒤에 방법론
KV 캐시 크기는 모델의 품질을 희생하지 않고 너무 작습니다. DeepSeek는 매우 저렴한 가격으로 장기 캐시를 제공 할 수 있습니다. Sonet 4.6 캐시의 3 % 미만 인 가격은 시간 동안 캐시를 유지할 수 있습니다。
긴 사이클 작업의 경우, 작은 KV 캐시는 필요한 경우 SSD로 더 경제적으로 다시로드 할 수 있다는 것을 의미합니다. 즉 HBM에 의존도를 줄일 수 있습니다. 중국의 AI 하드웨어 산업의 전망의 관점에서 HBM은 꽉 공급뿐만 아니라 만들 수있는 가장 어려운 유형의 메모리 중 하나입니다。
또한 DeepSeek는 SSD에서 KV Cache의 빠른 로딩에 대한 기술을 개발했으며 이중 경로 용지에 설명되었습니다。
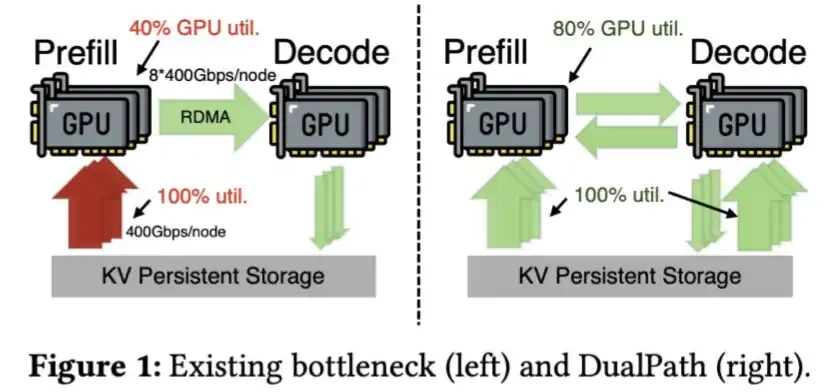
KV 캐시의 DeepSeek V4 압축은이 단계가 필요하지 않을 정도로 큰 것입니다。
그래서, 누가 KV 캐시 압축의 직접 beneficiary
누가 SSD를 공급합니까? 기억하십시오, YMTC는 3D 낸드 분야에 있는 거대로 성장합니다. NAND는 DeepSeek가 KV를 계산하는 두 배를 피할 것을 도울 수 있습니다. 턴에서 DeepSeek는 NAND 및 SSD에 대한 거대한 시장을 만들었습니다. Yangtze 저장뿐만 아니라 다른 관련 제조업체。

그러나 NAND와 SSD에 대해서도 없습니다。
LPDDR 메모리도 큰 잠재력을 가지고 있습니다. 그것은 모델 무게의 저장소 역할을하고 필요한 경우 HBM에 이러한 무게를 전송 할 수 있습니다, 따라서 HBM 수요에 압력을 증가. 좋은 블로그는 SGLang 팀에 의해 출판되었습니다. 아래 차트는 프로그램 작업 방법을 보여줍니다。
DeepSeek는이 프로그램에 대한 특정 디자인을 가지고 있지 않지만 MoE 아키텍처는 전문가 모델의 많은 수와 4bit 무게 특성이 토지에 쉽게 만듭니다。
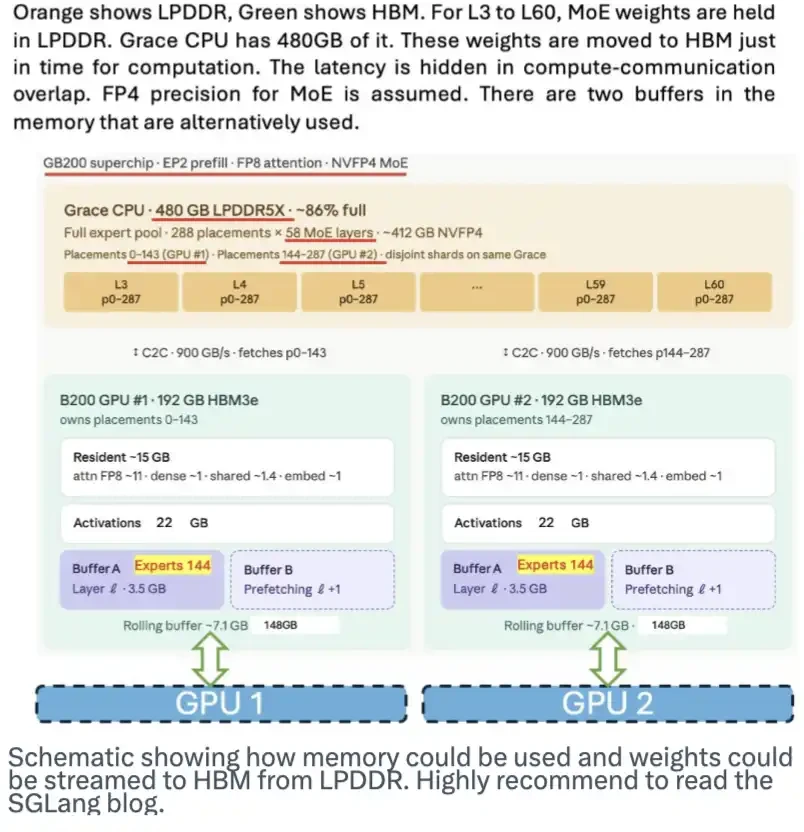
이 다이어그램은 메모리가 사용될 수 있으며 모델 무게가 LPDDR에서 HBM으로 전송 될 수 있습니다. 이 게시물은 우리의 특별한 적용 Global Voices 2011의 일부입니다。
이 혁신은 극단적으로 콤팩트와 결합될 때, intact KV 캐시는 HBM를 위한 수요를 두드러지게 감소시킬 것입니다。
그래서, 누가 중국에서 LPDDR 생산? 대답은 장기 저장인 CXMT입니다. 그들은 LPDDR 속도 뒤에 단지 반 발생, 그들은 밀도의 큰 차이는 아니다。
충분한 NAND 외에도 중국 AI 생태는 미래의 LPDDR 공급이 충분합니다. 압력을 쉽게합니까? 대답은 예입니다. 자주 묻는 질문。

GPU / ASIC 압력을 줄이기 위해 스마트 메모리 사용
KV 캐시를 저장하기 위해 NAND의 사용은 쉽게 이해할 수 있습니다 : 그것은 KV 캐시가 더 길게 유지하고 HBM의 압력을 줄이고 KV 캐시의 이중 계산을 피하면서 GPU 및 ASI의 계산 부담을 줄일 수 있습니다。
그래서 유사한 방법으로 LPDDR 일? 그것은 더 계산 압력을 감소시킬 수 있습니다, 무게 교류가 HBM "AS-YOU-GO"로 이동될 수 있는 저장 위치 이외에
대답은 예입니다。
LPDDR은 Engram이라는 대량의 콘텐츠를 저장할 수 있습니다. DeepSeek의 Engram 종이에서 MoE가 계산 조건으로 모델 용량을 확장 할 수 있다고 지적했지만 변압기는 원래 "knowledge search" 메커니즘이 부족했습니다. 따라서, 변압기는 종종 계산을 통해 비효율적인 방식으로 검색 프로세스를 시뮬레이션해야합니다。
이 문제를 해결하기 위해 DeepSeek는 Engram 모듈을 발표했습니다. Hashi를 기반으로 한 O-(1) 검색 메커니즘에 내장된 고전적인 N-gram을 현대화하고, 조건 메모리를 호출하는 보완 및 희석 된 경로 만들기。
계산 저축의 이 방법, 또한 자체에서 아주 큰 수 있는 embedding 테이블을 나르는 기억을 요구합니다。
본질적으로, 그것은 전형적인 기억 교환 공식입니다. 그러나 중요한 통찰력은, 각 비트 데이터를 읽는 비용에서, 기억의 이 측은 매우 더 싼 -- LPDDR 수색은 다중층 변압기 앞으로 계산 보다는 매우 더 싼 입니다. 따라서, 큰 규모에, 이것은 매우 수익성 교환입니다。
DeepSeek가 메모리의 일부를 희생함으로써 저축을 계산하는 방법입니다。
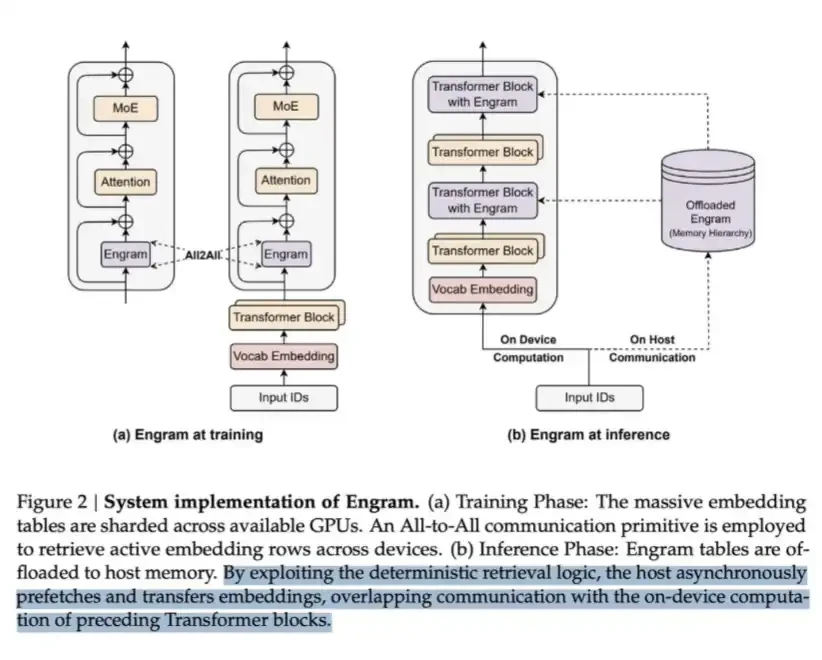
좋은 가치
결정 조밀도와 EUV의 동일한 수준 없이, 중국 GPU 및 ASIC는 그것의 본래 FLOPS 산법에 있는 서쪽 GPU의 뒤에 긴 래치 할 것입니다. 진보된 바다표범 어업에 있는 또한 뜻깊은 간격 있습니다. 이러한 거래 오프는 특히 중국이 대량의 NAND 및 LPDDR 메모리를 생산할 수 있다면 따라서 매우 가치가 있습니다。
DeepSeek의 장기적인 전략
이 혁신에서 DeepSeek는 수십억 달러의 수익을 창출하는 것을 목표로하지 않습니다. 선택의 많은 그것은 과거에 설명 했다: 지금까지, 거기 다공성, 음성 모델, 훨씬 적은 비디오 모델。
환자, 10 조 달러에 도달 할 수있는 장기 게임에 정말 참여했습니다. 대체 AI 하드웨어 생태를 홍보합니다。
이것은 중국의 국내 생산업체를 세계 AI 하드웨어 시장에서 주요 플레이어뿐만 아니라 자원 요구 사항을 근본적으로 줄이고 AI의 교육 및 서비스를 더 비용 효율적으로 만듭니다. 결과적으로 많은 GPU, ASIC 및 네트워크 칩 제조업체는 VIABLE 옵션이 될 수 있습니다。
동시에, 이러한 혁신은 웨스트의 오픈 소스 생태와 하드웨어 제조업체의 새로운 세대를 얻을 것이다。
모든 징후는 실제로 등장했습니다. DeepSeek가 지금까지 제안 한 혁신을 자세히 살펴 보겠습니다
전문가 혼합 모델 (MoE) 및 MLA는 DeepSeek V2에서 도입했습니다
DeepSeek는 V2의 MoE 및 MLA를 도입했습니다. MoE는 약 40 ~ 50 퍼센트로 높은 스마트 모델을 훈련하는 데 필요한 컴퓨팅의 양을 줄였습니다. MLA는 90 퍼센트로 KV 캐시를 줄였습니다。
이것은 SSD에서 KV 캐시를 언로드하는 매우 효율적입니다。
이 아이디어는 5 월 2024에서 DeepSeek에 의해 첫 게시되었습니다. 나중에, 그들은 또한 DeepSeek V3 훈련의 기초를 두었습니다. 그 당시 DeepSeek는 2048의 약화 된 H800 GPU를 사용하여 닫히는 소스 모델 레벨에 가까운 성능을 가진 시스템을 훈련했습니다。
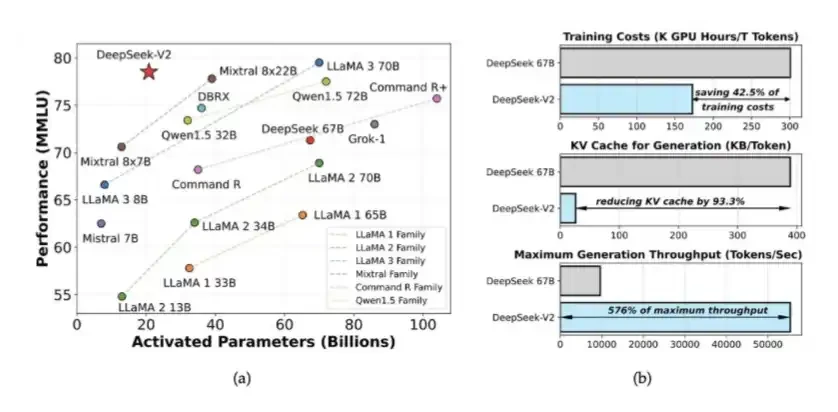
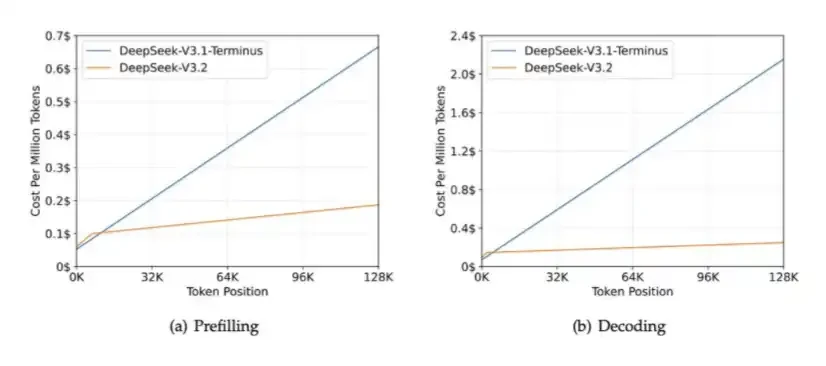
2. DSA: DeepSeek V3.2에서 소개하는 HBM 대역폭 압력을 mitigating하면서 긴 컨텍스트 시나리오에서 계산 비용을 줄일 수 있습니다。
DSA의 중앙 역할은 계산 된 볼륨은 상황에 따라 증가하지 않습니다. 아래 차트는 DeepSeek-V3.2의 처리 시간이 크게 증가합니다。
3 MHC : DeepSeek는 종이 mHC에서 12 월 2025에서 발표했습니다. 매니 폴드 - 제약 하이퍼 연결。
mHC는 DeepSeek의 매크로 구조 수준에서 혁신, 변압기 층 사이의 정보 흐름을 재설계。
과거에, ResNet부터, 모형은 보통 표준 잔여 연결을 이용합니다, i.e. x + F (x). MHC는 다른 한편으로는 여러 병렬 정보 채널에 잔여 스트림을 확장하고 모델이 혼합을 배울 수 있습니다. 이 점은 하이브리드 매트릭스를 더블 랜덤 매트릭스로 묶고, 이는 싱크호크-Knopp 프로젝션을 통해 Birkhoff polyhedrus로 제한하는 것입니다. 이 방법에서는, mathematically, 신호 범위는, 모형이 겹쳐 쌓인 방법에 관계없이 안정되어 있습니다。
이것은 이전에 비바운드 하이퍼 연결에 의해 직면 한 catastrophic 불안정성. Hyper-Connects는 byte에 의해 처음 발표되었지만, 구속하지 않고, 신호는 일반 회의에 의해 전송되었다 3000 배의 크기 27 억 매개 변수, 훈련의 전체 붕괴에 선도。
mHC의 계산 비용은 매우 낮습니다. 실제 교육 시간의 6.7 퍼센트에 대해 비용이 들지만 주의 층 또는 FLN 층을 변경하지 않기 때문에 간단히 레이어 사이의 이러한 층의 출력의 모드를 변경합니다。
그러나 성능은 매우 중요합니다. 27 억 매개 변수의 크기에서 mHC는 BIG-Bench Hard reasoning 작업에 7.2 포인트를 올리고, DROP의 3.2 포인트, GSM8K 수학 작업에 2.8 포인트 및 MMLU 일반적인 지식 작업에 1.4 포인트. 이 증가는 동일한 모형 크기 및 거의 동일한 계산 예산의 밑에 달성되었습니다。
본질적으로, mHC는 더 높은 단위 매개 변수 인텔리전스를 달성하여 정보 경로의 교차 층을 확장하여 더 값 비싼 네트워크, 작은 추가 FLOPS。
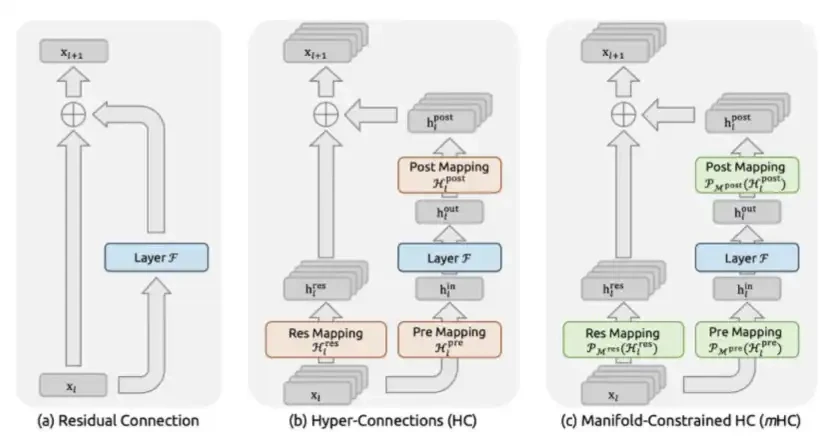
mHC는 복잡한 건축 설계이지만 더 안정적인 교육 프로세스와 더 높은 단위 매개 변수 인텔리전스로 이어질 수 있습니다。
CSA, HSA : DeepSeek는 4 월 2026에서 V4에 도입되었습니다。
CSA 및 HSA는 KV 토큰을 압축함으로써 KV 캐시 수요를 90 % 감소시키고 필요한 FLOPS를 크게 줄이며 HBM 및 GPU / ASIC 압력을 증가시킵니다。
5- Engram : DeepSeek는 2026 년 1 분기에 도입되었으며 메모리를 사용하는 데 필수적인 i.e. LPDDR, 컴퓨팅 효율 교환。
아래의 세부 차트에서 표시된 것처럼 전체 매개 변수 예산은 동일하지만 Engram은 상당한 성능 개선에 대해 가져 왔습니다。
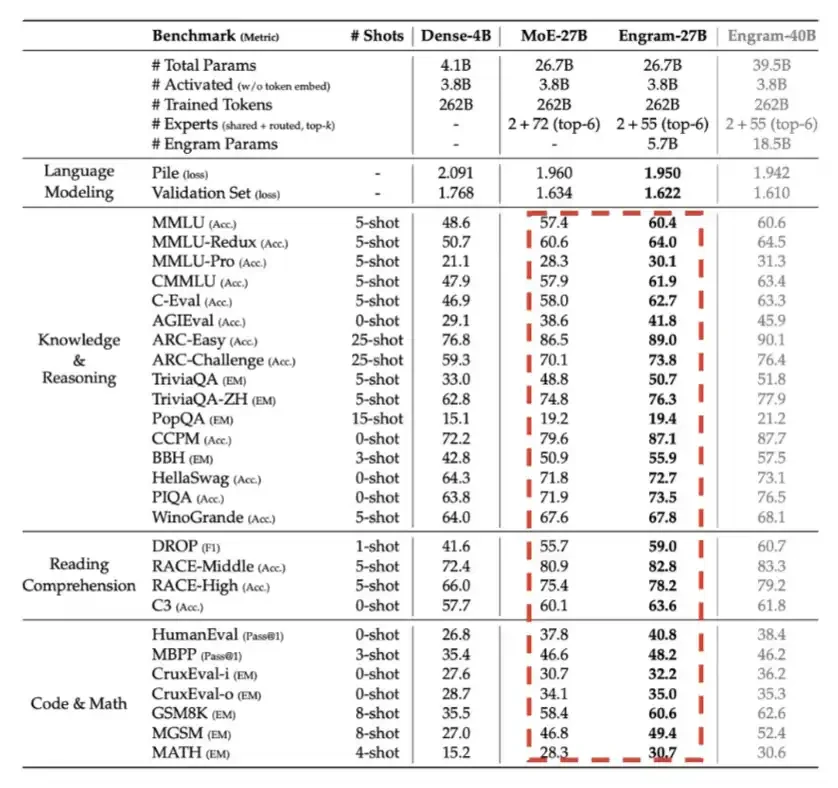
6 Engram : DeepSeek는 2026 년 1 분기에 도입되었으며 메모리를 사용하는 데 필수적이며, i.e. LPDDR은 컴퓨팅 효율성을 교환합니다。
아래의 세부 차트에서 표시된 것처럼 전체 매개 변수 예산은 동일하지만 Engram은 상당한 성능 개선에 대해 가져 왔습니다。

DeepSeek의 제안은 V4 용지에 하드웨어 제조업체와 공유합니다. 나는 그들이 온라인 커뮤니케이션에 더 많은 의견을 줄 것이다 확실합니다。
7. 동일한 방향에 있는 TileLang 점에 입력: DeepSeek는 단지 그의 자신의 math bottlenecks를 두지 않습니다, 그러나 서쪽 생태와 경쟁하기 위하여 중국의 기계설비 생태를 몰고 있습니다。
TileLang의 도움으로, 개발자는 한 번만 커널을 준비할 수 있습니다, 즉, 계산하기 위하여 사용된 더 낮은 부호, 그리고 그 후에 다수 기계설비 플랫폼에 성공적으로 실행하고, 제공된 그들은 대응 TileLang 백엔드 지원을 비치하고 있습니다。
다른 중국 AI 실험실을 기대합니다. 이것은 중국 하드웨어 제조 업체가 소위 CUDA MOAT와 간접적으로 거래하는 데 도움이됩니다. 동시에 AMD와 같은 더 많은 WESTERN 하드웨어 잠재력을 출시합니다。
중국의 AI 하드웨어 플랫폼이 이미 CUDA 호환성 기능을 제공하거나 CUDA 번역 레이어를 제공해야한다고 지적해야합니다. 예를 들어, Moor 스레드, 머셀, 벽 뚜껑 및 일 코어는 CUDA 호환성이 transliteration 층을 통해 높은 중국 칩 제조업체입니다. 그래서 이론적으로, 그들은 반드시 타일Lang을 필요로하지 않습니다。

대규모 학습 및 RSI
DeepSeek는 calculus, i.e., 더 많은 유효한 기계설비의 근원을 취득하고, 모형 자체는 계산 리소스를 위한 수요를 감소시킵니다, 그것은 더 야심 찬 훈련 프로그램을 전진할 수 있습니다, 특히 포스트 학습 훈련。
향상된 학습은 많은 궤적의 세대를 필요로, 즉 토큰의 조. 이 과정은 곧 매우 비쌉니다. 1백만개의 컨텍스트 길이의 모델이 훈련되는 경우에, 동일한 길이의 trajectory는 필요합니다. 이 superlong trajectory에 훈련 모형은 진정한 긴 주기 임무를 지원할 수 있습니다。
또한 하드웨어 옵션 증가로 DeepSeek는 자동화 된 연구, 즉 RSI를 촉진 할 수있는 더 많은 하드웨어 리소스가 있습니다. RSI는 AI 설계 및 자체 실험을 수행합니다. 이러한 접근법은 많은 수의 테스트 오류와 비용의 급속한 증가를 포함 할 것입니다. 그러나 RSI는 완전한 모형 디자인 공간을 탐구하기를 위해 근본적입니다. DeepSeek는 AGI 또는 ASI로 가기 전에 RSI 기능이 있어야 합니다。
DeepSeek, 오늘, 전체 산업은 내일을 따를 것입니다. 오시는 길
DeepSeek는 전문가 잡종 모형, MLA, DSA의 방향에 있는 혁신, 등 세계와 중국에 있는 다른 AI 실험실에서 소개되었습니다。
예를 들어, GLM 시리즈 모델 ZAI는 MLA와 DSA를 사용했습니다. Kimi, 또는 Moonshott는 MLA를 사용하며 구조가 DeepSeek 아키텍처를 기반으로합니다. 턴에서 DeepSeek는 Kimi (Moonshott)의 대규모 교육에서 처음 사용 된 Muon Optimizer를 사용합니다。
그것은 그것을 주목해야한다:
MoE는 2017 년 Google에 의해 처음으로 제안되었으며 키 저자는 Noam Shazeer입니다. DeepSeek의 기여는 큰 규모의 MoE를 사용하고 기술을 발명하기 위해되었습니다。
Muon, Newton-Schulz Optimizer의 MomentUm Orthogonalized는 Keller Jordan, 2024 년 말에 기계 학습 연구가 발표되었습니다. Kimi (Moonshot) 팀은 대규모 훈련을 위해 그것을 사용하는 첫번째였습니다。
돈 만들기에 대해
우리는 흥미로운 예로 OpenAI를 볼 수 있습니다。
OpenAI는 AMD와 Cerebras sharehold/option을 저렴한 가격으로 획득했습니다. AMD 및 Cerebras의 경우 매우 수익성있는 거래입니다. 한 번 OpenAI는 하드웨어를 사용하기 위해 최선을 다하고 있기 때문에 긴 실행의 성공의 끝은 극적으로 증가합니다。
AMD BULLETIN은 성명을 포함합니다:
"계약의 일부이며, 두 당사자의 전략적 관심사를 더욱 해치하기 위해 AMD는 OpenAI에게 특정 이정표의 성과에 따라 점차적으로 속성 될 AMD 일반 주식의 최대 160 백만 주식의 소유권 인증서를 발행했습니다. 첫 번째는 초기 1 Giwa 배포의 완료에 따라 속성이 될 것이며, 후속 배치는 조달 규모가 6 Giwa로 확장됩니다. Attribution 조건은 대규모 AMD 배포에 필요한 기술 및 상업적 이정표의 AMD의 특정 주식 가격 목표 및 OpenAI의 업적과 연계됩니다

DeepSeek는 여러 가정 기반, ASIC, CPU 및 네트워크 기술 매장과 유사한 계약을 체결하여 AI 부하를 선도할 수 있는 하드웨어 저장소를 구축할 수 있도록 합니다。
East Asian allies를 포함한 모든 West가 AI equities에서 $ 10 조 이상의 총 시장 가치를 가지고있는이 "co-operative equity return" 접근법은 DeepSeek에게 중국이 자신의 케이크를 분할하는 동시에 큰 산업을 구축 할 수있는 기회를 제공 할 것입니다. 궁극적으로 $ 1 조의 valuation을 달성。
DeepSeek는 전통적인 응용 프로그램을 넘어가는 사업에서 돈을 벌뿐만 아니라 모든 사람들을 위해 AGI 작업을 만드는 목표라는 것을 달성 할 것입니다. Liang Wensai는 짐 시몬스와 똑똑한 충분한 자본 선수의 큰 팬이고, 그는 그것을 놓을 수 없습니다。
DeepSeek가 지금까지 수행 한 것을 보면 감각을 만드는 유일한 설명입니다。
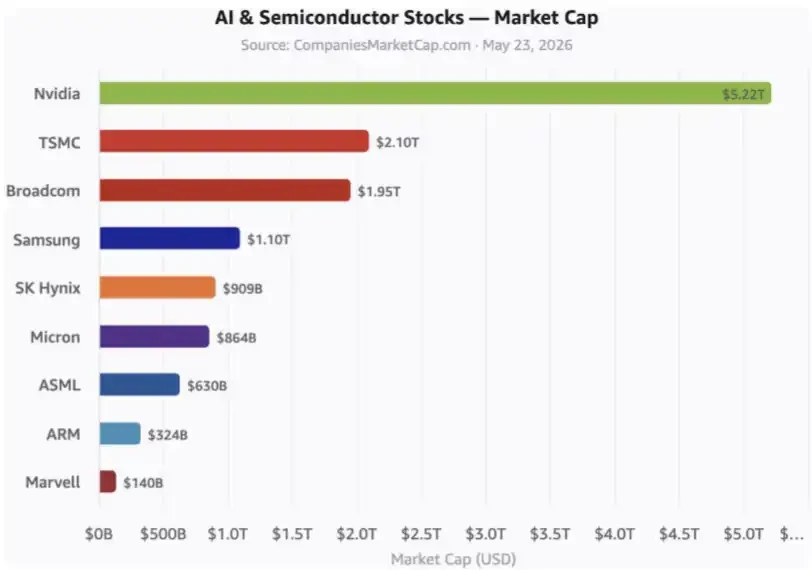
이것은 중요한 AI 주식입니다. 숫자는 하이퍼, 즉 슈퍼 큰 클라우드 제조 업체 및 기타 관련 회사를 포함하지 않습니다。
