
5分。 第二の脳をAIにする
記憶をAIに発信する時間です

元のタイトル: クロード コード + オブシディアン究極のガイド
原作:AIエッジ
ペギーブロックビートによる写真
編集者:この論文は、ClaudeコードとObsidianに基づいて個人的な知識システムを提示します, そのコアは、もはや従来のRAGモデルの下で「すべてのクエリ, 一時的な検索」の使用ではありません, しかし、AIが進化する知識ベースを構築し、維持できるように試み (Wiki) 継続的な基礎。
構造的に、システムは3つの層に分けることができます:
一つは、ノート、記事、翻訳などの非修飾入力ソースを含む、生のデータ層です
•第二に、AIによって維持される構造化された知識ベースは、継続的な更新で相互参照と関係構築を完了します
•第三に、スキーマルールレイヤーは、知識を整理し、システム操作のロジックを調節します。
この構造の周りでは、システムは3つのコア操作で動作します: 摂取(ingestion)は、外部情報を継続的に統合します。 クエリ(クエリ)は、知識の即時転送を実現します。 構造的な一貫性と潜在的な問題の修復に使用されます。
この仕組みでは、一度の対話の結果に知識が合わないが、徐々に再利用可能な長期資産として「書き込みコレージュリユース」サイクルで入金される。 このように、このモデルは「コンパウンド」と似た知識に対する累積的な効果があることを示唆しています。一方、それは個人に対する認知負荷を軽減し、一方、モデルの出力の正確さとコンテキストとの一貫性を高めます。
ただし、連続入力とメンテナンスの前提に基づいて、システムの効果的な操作も行います。 安定したデータ注入および構造更新の不在では、この「第2の脳」実質の累積的な効果を持っていませんし、その利点は減少します。
以下は元のテキストです
クロードコード+オブシディアン、私が今まで使った最強のAIの組み合わせ。
私はほとんどすべての私の考え、読書、執筆、オンライン研究を含む「AI第二脳」を構築しました。 それは私のビジネス計画、すべての私のYouTubeのビデオ、記事、私に重要なすべてが含まれています。
クロードコード+オブシディアンは様々なプラットフォームですぐに人気を博しており、事故はありません。
個人的には、このAIシステムは、認知の負担を大幅に削減し、ビジネスや個人的な生活に重点を置いています。

私のクロードコード + オブシディアンシステム
システムが複雑に見えるかもしれませんが、実際にビルドするには5分かかります。 より重要なのは、それ自身が使用しているように最適化する独自のメモリ機構です。
そして、私は実際にあなたの効率を改善するこの「AI秒脳」システムを再作成するために一度に1つのステップを取るつもりです。
記事の最後に読むことをお勧めします - 私は完全なClaudeコード+ Obsidian操作回路図とテキスト(すべて無料)に記載されているすべてのリソースを添付します。
はじめに
システムはもともと私によって作成されず、LLMの知識ベースについて数日前、アンデルジ・カルパシーのブラストツイートに触発されました。
参照: https://x.com/karpathy/status/2039056595525644595
このツイートは、現在のAI開発において重要なポイントに取り組むアイデアを提供するため、急速に再構築されます。
問題は、新しい会話を開始したり、新しいAIツールに切り替えるたびに、ヒントを再変換し、コンテキストをゼロから追加する必要があります。
この一連のシステムヒントをObsidianとClaudeコードと組み合わせることで、AIの出力の質を大幅に向上させながら、この問題は徹底的に解決することができます。
システムの仕組みは
システムは4つの中心モジュールから成っています:
1. あなたのデータ:記事、ノート、転写、インスピレーションのアイデア、等を含む
2. 組織:落語のクロード・コードによって自動的に分類される
3. 即時呼び出し:このデータベースに回答を求めることができます
4. 進化記憶:使用されるようにシステムがよりスマートになります
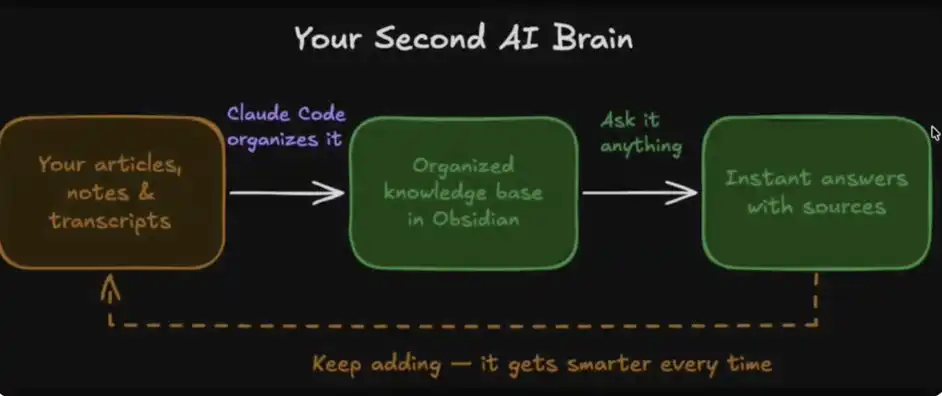
あなたのAI、第二脳
このシステムの実力は何ですか
人間の存在として、認知帯域幅は限られています。 忘れてみると、異なるアイデアを繋げるのが難しいこともありますし、同時に追跡・加工できる情報は、最終的にはキャップされます。
そして、この4モジュールシステムでは、実際に認知の負担を解放し、ObsidianとClaudeコードへの接続、調整、理解に関する情報のタスクを委託しています。
あなたのアイデアは体系的にリンクされ始めます, 1つのノートは、自動的に互いにリンクされています, あなたはいつでもクラウデを介してそれらを再描画することができます, グループと呼び出します。
この構造では、あなたの知識はもはや断片化されていませんが、むしろ、天井がほとんどなく、継続的に呼び出され、再編することができるネットワーク。
5分でAI脳を構築する方法
1. Obsidianをダウンロード
公式ネットワーク:https://obsidian.md/
https://obsidian.md/
2. Vault を作成する
ダウンロード後、Obsidianは「Vault」を作成するためにあなたに警告します。
全てを格納し、Claude Codeにアクセスしてデータを管理するコンピュータ上のフォルダとして解釈できます。
このVaultの名前はランダムで設定できます。例えばObsidian Vaultと呼びます。
Obsidian Vault(ナレッジベース)
このVaultは、Obsidianがすべてのデータとメモを保存し、MD(Markdown)ファイルに保存されます。
3. セットアップ クロード コード
次に、Claudeコードにアクセスする方法を設定する必要があります。 一番シンプルな方法は、デスクトップクライアントを直接使うことです。
メインチャットインターフェイスで、「フォルダーを選択」をクリックし、新しく作成したObsidianVaultを見つけて選択します。
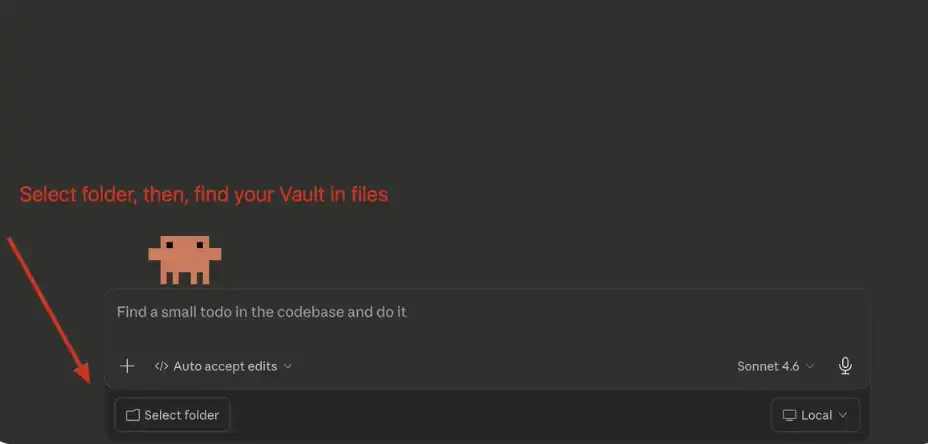
クロードコード:あなた、ボルトに接続
4. セットアップ システム インデックス(システム プロンプト)
フォルダを選択すると、次のステップは、メインチャットボックスにAndrej Karpathy のシステムヒントを貼り付けることです。
ヒントをコピーできますhttps://gist.github.com/karpathy/442a6bf55591483e9891c115de94f

入力は次のようになります
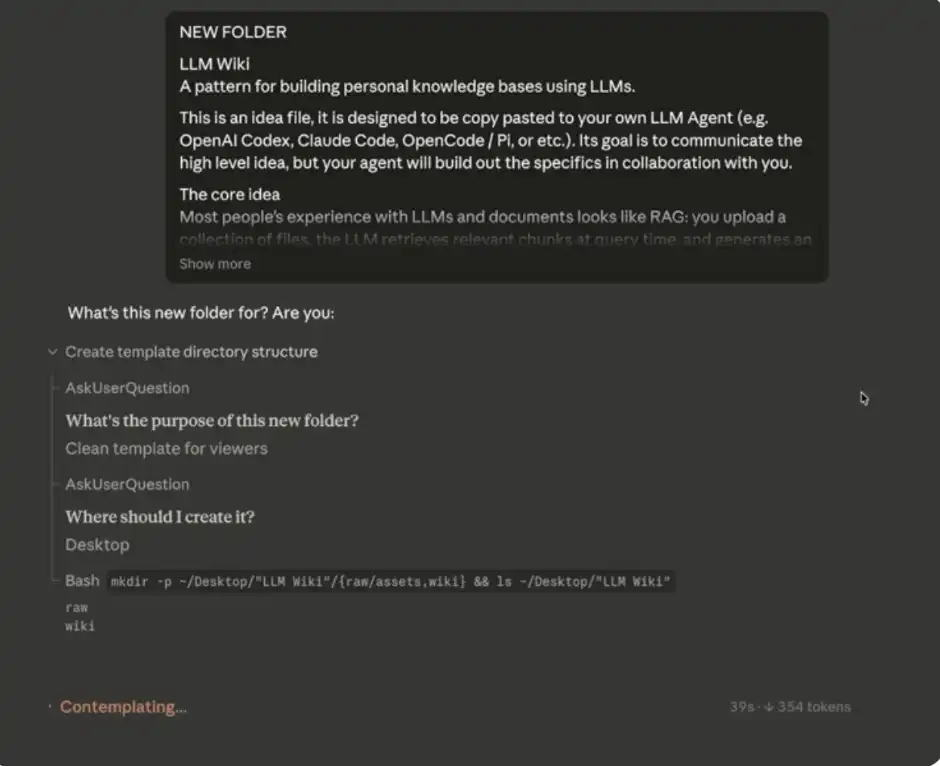
クロードコード初期入力
リトルチップ: 望まない場合は、手動で開くことができます。 MDフォルダ(つまり、Vault)と関連データがClaudeコードに渡す限り、これらのファイルを直接読み、書き、変更することができます。これらは、Obsidian "second brain"に自動的に同期されます。
5. データライブラリの構築
システムヒントで完了すると、Claude Code は、2番目の脳を初期化し、徐々に埋めるために使用できるデータソースについて尋ねるようになります。
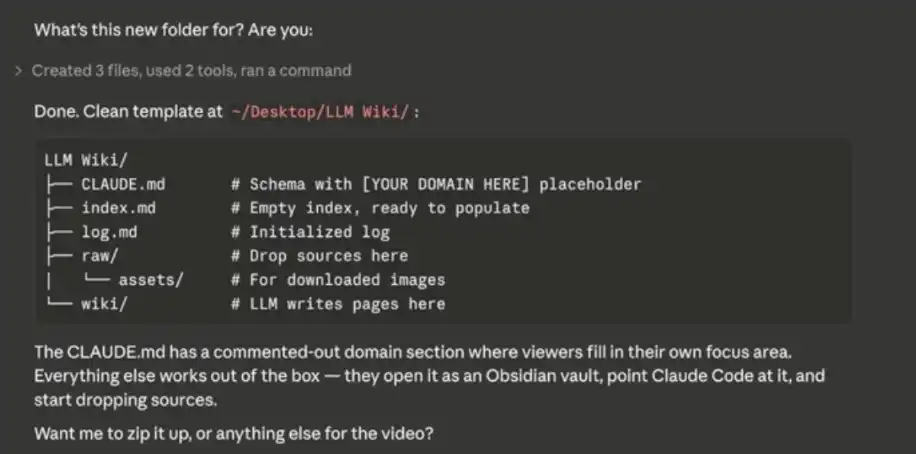
データベースの構築
「空のノート」としてオブシディアンを想像できます。コンテンツから始める必要があり、データベースが構築されます。 メモ、CSVファイル、Markdown/テキストファイルをインポートすることができます。
いくつかの実用的な提案:
既存のノートブックツールからデータをエクスポート
. Notion を使うと CSV ファイルとしてエクスポートできます
ジャン・クラウデは、あなたの2番目の脳を開始するためにあなたについてのメッセージを整理しました
• 既存の記事、コレクション、インスピレーションなどをインポート 初期データを作成するのに最適なタイミングで、いつでもフォローアップができます
鉱山などの大量のデータを持つデータベースはすぐに利用できず、時間が経つにつれて蓄積されることが重要です。

私のデータベース
です。 「AI第2脳」が準備完了です。 そして、私はいくつかの進歩を共有し、より効率的にそれらを使用するのに役立ちます。
プロのヒント
1、肥満Crome拡張プラグイン
簡単にシステムにデータを追加したい場合は、OBsidian Chrome拡張をインストールする必要があります。 Webページで「Obsidianに追加」をクリックし、知識ベースでコンテンツを保存することができます。 これは、2番目の脳を非常に簡単に構築するプロセスになります。
私は、記事、Webデータ、研究資料などを収集するために、この機能を使用することが多いです。
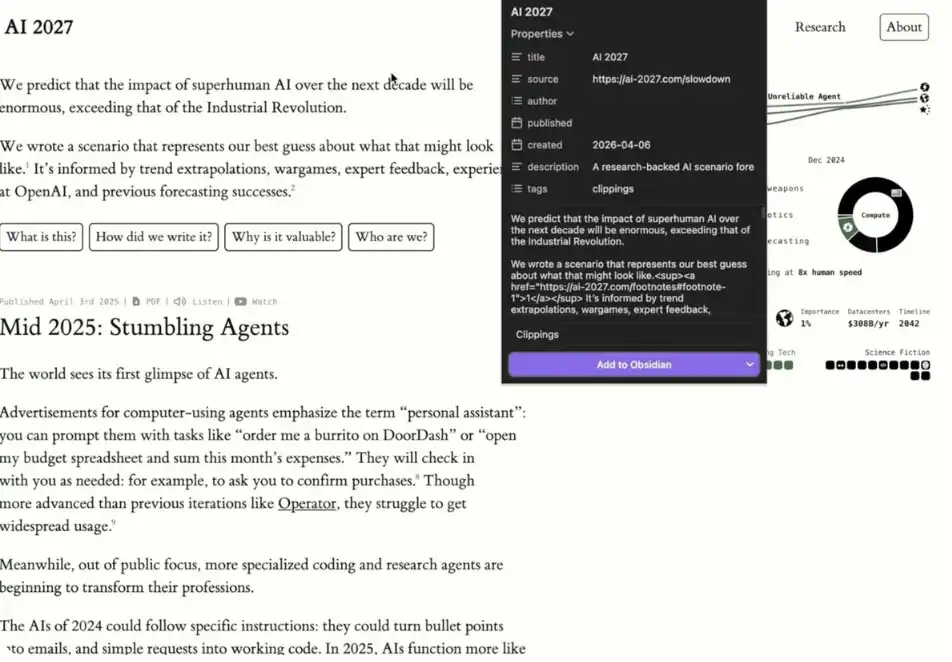
例:肥満症の爪で拡大
拡張で追加されたデータが初期に「サイレントデータソース」だったことに注意することが重要です。
すると、Claudeコード、「私はちょうどObsidianに[x]を追加し、私はWikiにそれらを統合するのに役立ちます」と伝えることができます
Claude Code は、これらの新しいデータを既存のコンテンツに自動的に接続し、それを真に第二の脳に統合するリンクを作成します。 そのため、ツールのセットはとても強力です。
2 別々のフォルダーを作成する(Vault)
Andrej Karpathy は 2 つの別々のフォルダー (Vault):
•仕事/商業内容のための1つ
•個人的な生命/ターゲット管理のための1つ
私の自身の使用経験は最も明確で、最も有効な構造です。
3. 実用性
私はシステムの中で最も価値のある用途の1つを見つけました。それは本当に簡単です。LMのヒントをより正確にするために。
モデルは、あなたの完全な個人情報、ビジネス計画、書き込み背景などにアクセスできるとき、それはより多くの「提案」であり、より現実に関連した高品質のヒント(さらに「スーパープロンプト」)を生成することができます。
もちろん、システムがよりはるかに便利であるが、最も実用的なシナリオの1つだけから始めるのであれば、「アップグレード品質」から始めることを強くお勧めします。
4、孤児(分離中)
Obsidianでは「Orphans」とは、他のノートにリンクされていないデータポイントを指します。
それはあなたを助けるので、それは便利です:
•まだ統合されていないアイデアを見つける
データベース内の「弱いエリア」の特定
:: さらなる拡大や深化の価値を判断する
つまり、単なるソートツールではなく、ブラインドゾーンについて考えるための仕組みです。

孤児(隔離されたノード)
右上隅にある「3つの点」をクリックし、Orphansスイッチをオンにして接続されていないものを見ることができます。
システムの潜在的な欠点
多くの利点の不十分性、シーンの使用、すでに説明した最適化方法は何ですか? システムの使用に合わない状況は
視覚化に使用されていない人
システムの中央の利点は、データを視覚化できるということです。 自分でこのアプローチに頼りにならず、慣れていない場合は、あなただけの限られた援助かもしれません。
2. 一定の維持費の必要性
データベースを継続的に維持したくない場合は、システムが適さない場合があります。 メンテナンスコストが高くなりますが、データが一貫して2番目の脳に入らないと値をつけることは困難です。
3. 貯蔵職業
すべてのコンテンツは、Markdownファイルとしてローカルに保存され、特定の機器スペースを占有します。 事前に検討する必要があります。
[ チャック ]オリジナルリンク]
