
a16z: Amnesia for AI, can continuous learning "cure" it
The breakthrough is the thing that makes models strong when they are deployed and trained: compression, abstraction, learning。

Original title: Why We Need Periodic Learing
Original by Malika Aubakirova, Matt Bornstein, a16z crypto
Original language: Deep tide TechFlow
In Christopher Nolan's Memento, the leading actor, Leonard Shelby, lives in a broken moment. The brain damage caused him to suffer from procrastination and loss of new memory. Every few minutes, his world is reset, trapped in the eternal "at this moment" — remembering what just happened and wondering what's going to happen. In order to survive, he has written and filmed his body to replace memory functions that the brain cannot perform。
Big language models live in similar eternal times. After the training, the mass of knowledge is frozen in parameters, and models do not create new memories and do not update their parameters in the light of new experiences. To fill this gap, we put it on scaffolds: chat history as a short-term handprint, retrieval systems as external notebooks, system hints as tattoos. But the model itself has never really internalized this new information。
A GROWING NUMBER OF RESEARCHERS CONSIDER THIS TO BE INSUFFICIENT. CONTEXT LEARNING (ICL) SOLVES PROBLEMS IF THE ANSWER (OR THE FRAGMENT OF THE ANSWER) ALREADY EXISTS IN SOME PART OF THE WORLD. BUT THERE IS GOOD REASON WHY MODELS NEED A WAY TO INCLUDE NEW KNOWLEDGE AND EXPERIENCE DIRECTLY IN THE PARAMETERS AFTER DEPLOYMENT, FOR THOSE PROBLEMS THAT NEED TO BE ACTUALLY DISCOVERED (E.G. A NEW MATHEMATICAL CERTIFICATE), FOR CONFRONTATIONAL SCENARIOS (E.G. SECURITY PRECAUTIONS), OR FOR KNOWLEDGE THAT IS TOO SUBTLE TO EXPRESS IN LANGUAGE。
context learning is temporary. real learning needs compression. until we allow the model to continue to compress, it may be trapped in the eternal moment of memory debris. conversely, if we can train models to learn their own memory structures, rather than relying on external customized tools, we can unlock a completely new scaling dimension。
This field is calledContinuous learning(continual learning) This concept is not new (see McCloskey and Cohen 1989 papers), but we consider it one of the most important research directions in the current AI field. The explosive growth of modelling capacity over the past two to three years has made the gap between models known and known increasingly apparent. The purpose of this article is to share what we have learned from top researchers in the field, to help clarify different paths of continuous learning and to contribute to the development of this topic in the entrepreneurial ecology。
Note: The shape of the article benefited from intensive exchanges with a group of excellent researchers, doctoral students and entrepreneurs who generously shared their work and insights in the area of continuous learning. From the theoretical foundation to the engineering reality of post-deployment learning, their insights have made the article more solid than we have written alone. Thank you for your time and thoughts
Let's start with the context
Before defending parameter-level learning (i.e. learning that updates model weights), it is necessary to acknowledge the fact that context learning does work. And there is a strong argument that it will continue to win。
The essence of Transformer is the next token predictor based on the conditions of the sequence. Give it the right sequence, you get amazingly rich behavior, and you don't need to touch the weight. That is why context management, tips, instructions fine-tuning and few sample examples are so powerful. Smart encapsulation is in static parameters, and the ability to show it changes dramatically as you feed into the window。
The recent in-depth article by Cursor on autonomous programming smarts scaling is a good example: model weights are fixed, and what really makes the system run is a fine layout of the context — what to put in, when to summarize, how to maintain consistency in a few hours of autonomous operation。
OpenClaw is another good example. It does not explode because of special model privileges (which are available to all at the bottom), but because it transforms context and tools into working conditions with great efficiency: tracking what you are doing, structuring intermediates, deciding when to re-introduce, and maintaining a lasting memory of previous work. OpenClaw raised the "shell design" of the intelligent to an independent discipline。
When prompting the project first appeared, many researchers were sceptical about the fact that "advertisements alone" could be a proper interface. It looks like a jack. However, it is the original product of the Transformer architecture, does not require retraining and is automatically upgraded as models progress. The model gets stronger, the hint gets stronger. The "simplistic but primitive" interface often wins because it connects directly to the bottom system, not to it. So far, LLM's trajectory is exactly that。
State spatial model: Steroid version of context
THE CONTEXT LEARNING MODEL IS UNDER INCREASING PRESSURE AS MAINSTREAM WORKFLOWS MOVE FROM ORIGINAL LLM TO INTELLIGENT CIRCULATION. IN THE PAST, IT HAS BEEN RELATIVELY RARE FOR CONTEXT WINDOWS TO BE FULLY FILLED. THIS USUALLY HAPPENS WHEN LLM IS ASKED TO PERFORM A LONG LINE OF DISCRETE TASKS, AND APPLICATION LAYERS CAN CUT AND COMPRESS CHAT HISTORY IN A MORE DIRECT MANNER。
But for an intelligent body, a mission may eat a large part of the context that is always available. Every step of the intelligent cycle depends on the context in which the first sequence is passed. And they often fail 20 to 100 steps later, because the line is broken: the context is filled, consistency is degraded, and it cannot be contained。
As a result, the main AI laboratory now devotes significant resources (i.e. large-scale training operations) to developing models for super-long context windows. This is a natural path, as it is based on methods that are already effective (learning in context) and is in line with the industry ' s general tendency to shift to reasoning. The most common structure is a fixed memory layer, i.e. a state spatial model (SSM) and linear attention variant (hereinafter referred to collectively as SSM), inserted between general attention. SSM provides a fundamentally better scaling curve in a context。
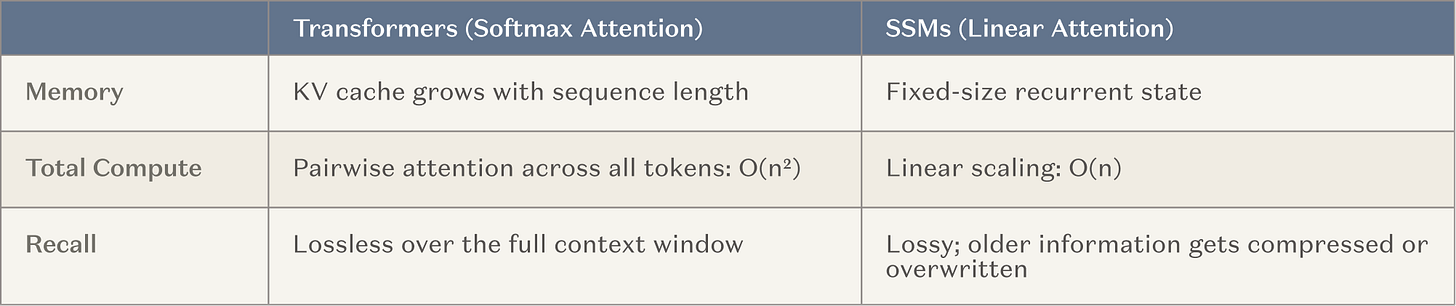
Figure: SSM compared to scaling of traditional attention mechanisms
The goal is to help the intelligent to raise the number of consistent steps up to several orders, from about 20 to about 20,000, without losing the extensive skills and knowledge provided by traditional Transformer. If successful, this is a major breakthrough for long-run intelligents。
You can even see this as a form of continuous learning: Although model weights were not updated, an external memory layer was introduced that hardly needed replacement。
So these non-parametric methods are real and powerful. Any assessment of continuous learning must start here. The question is not whether today's context system works, but it does. The question is: have we seen the ceiling, and can the new approach lead us further。
What's missing in the context
"AGI AND PRE-TRAINED THINGS HAPPEN THAT, IN A SENSE, THEY OVERWHELM... HUMANS ARE NOT AGI. YES, HUMAN BEINGS DO HAVE A SKILL BASE, BUT THEY LACK A GREAT DEAL OF KNOWLEDGE. WE RELY ON CONTINUOUS LEARNING。
If I make a super smart 15-year-old boy, he knows nothing. A good student, eager to learn. You can say, go be a programmer, go be a doctor. Deployment itself involves some kind of learning, testing and error. It's a process, not to throw the finished product out. Ilya Sutskever
Imagine a system with unlimited storage space. Each of the world ' s largest filing cabinets is well indexed and accessible. It can find anything. Did it learn
Nothing. It's never been forced to do compression。
This is the core of our argument, which quotes a point made earlier by Ilya Sutskever: LLM is essentially a compressed algorithm. In the course of training, they compress the Internet into parameters. Compression is damaging, and it is that kind of damage that makes it strong. Compression forces models to look for structures, generalize and construct signs that can move across the context. A model of a hard-backed sample of all training is not a model of a bottom pattern. Compression is learning itself。
IRONICALLY, THE MECHANISM THAT ALLOWED LLM TO BE SO POWERFUL DURING THE TRAINING (COMPRESSING RAW DATA INTO COMPACT, TRANSFERABLE MANIFESTATIONS) WAS PRECISELY WHAT WE REFUSED TO LET THEM CONTINUE AFTER DEPLOYMENT. WE STOPPED COMPRESSION AT THAT MOMENT AND REPLACED IT WITH EXTERNAL MEMORY。
of course, most smart body casings compress the context in some way. but isn't the bitter lesson that models themselves should learn to compress, directly and on a large scale
Yu Sun shared an example of this debate: mathematics. Look at Fermat theorem. For many years, no mathematician has proved it, not because they lack the right literature, but because the solution is highly novel. There is too much conceptual distance between the knowledge of mathematics and the final answer。
Andrew Wiles, when he finally took it in the 1990s, spent seven years working in isolation, having to invent new technologies to reach the answer. His certification relies on successful bridges to two different mathematical branches: elliptical curves and model forms. While Ken Ribet has previously proved that this connection can automatically solve the Fermatian Theorem, no one has the theoretical tools to actually build the bridge before Wiles. Grigori Perelman can do the same thing with the proof of Pongarai's guess。
The core issues are:Are these examples proof that LLM lacks something, some ability to update a priori and really think creatively? Or does the story just prove the opposite -- all human knowledge is data that can be trained and restructured, Wiles and Perelman, but show what LLM can do on a larger scale
The question is empirical and the answer is uncertain. But we do know that there are many categories of issues where learning below will fail today, and parameter-level learning may be useful. For example:

Figure: Context learning failure, possible problem categories for parameter learning
More importantly, context learning can only deal with what can be expressed in language, while weights can encode concepts that cannot be conveyed in words. Some models are too high, too invisible, too deep to be structured. For example, in medical scans, the visual texture that distinguishes a virtuous pseudo-tumour from the visual texture of a tumor, or the slight fluctuations in the audio that define the unique rhythm of a talking person, are not easily broken into precise vocabulary。
Language can only be similar to them. No longer a hint can convey these things; such knowledge can only survive within its weight. They live in the space of learning signs, not words. Regardless of the growth of the context window, there is always some knowledge that cannot be described in the text and that can only be carried by parameters。
This may explain why the obvious "robots remember you" function (such as ChatGPT's memory) often makes users uncomfortable rather than surprised. The user really wants not "remember" but "power." A model that has internalized your behavior patterns can be transposed to a new scene; a model that simply remembers your history can't. The difference between "this is what you wrote the last time you answered this e-mail" (repeated verbatim) and "I've understood your way of thinking enough to predict what you need" is the gap between search and learning。
Introduction to continuous learning
There are many paths to continuous learning. The dividing line is not "no memory" but:Where did the compression happenThese paths are distributed along a spectrum, ranging from uncompressed (pure search, weight freeze) to full internal compression (weight learning, models become smarter), with an important area (modules)。
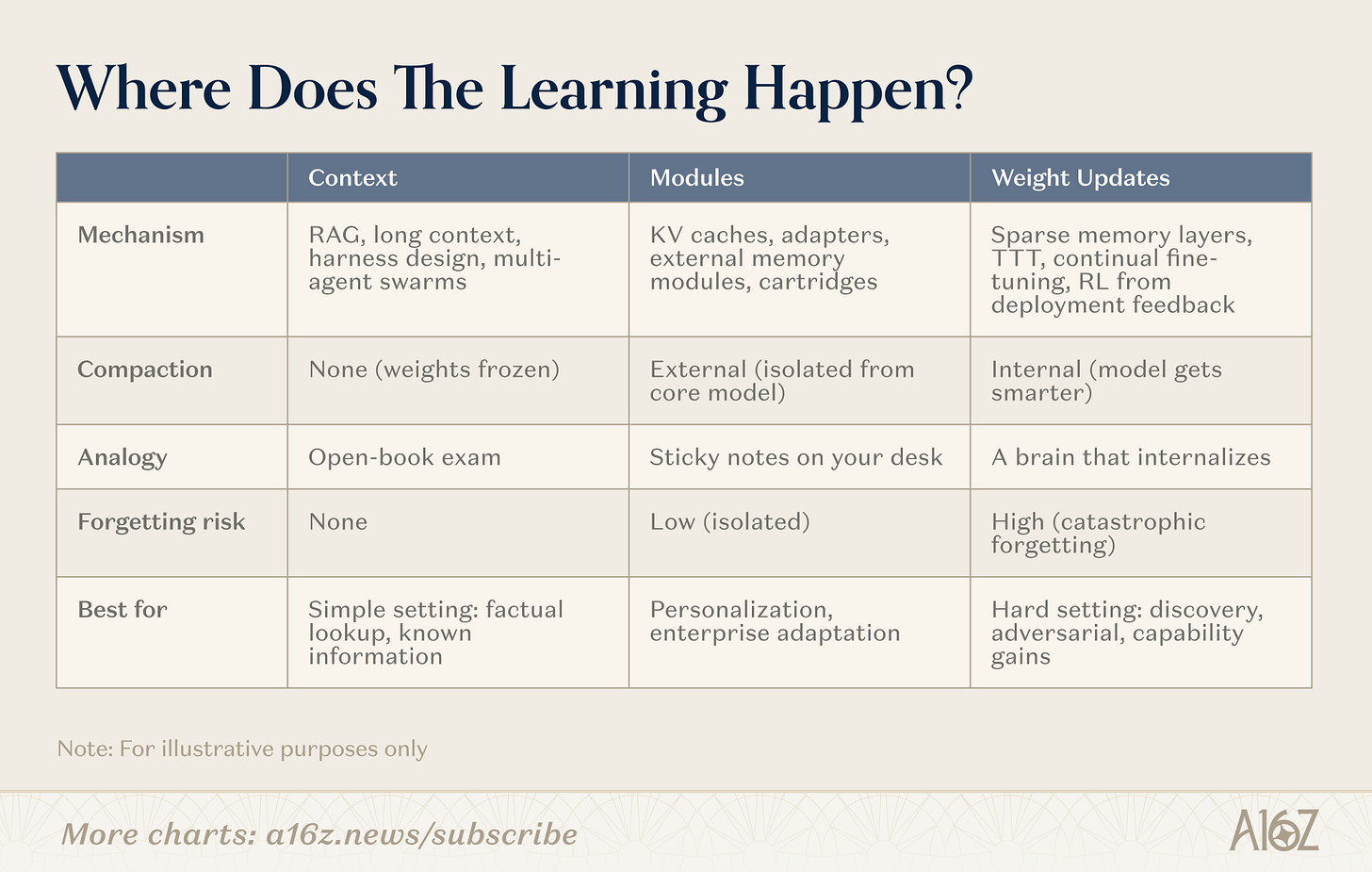
Figure: Three pathways for continuous learning - context, modules, weights
Context
At this end of the context, teams build more intelligent search tubes, smart body casings and hint organization. This is the most mature category: the infrastructure is validated and the deployment path is clear. The limit is depth: the length of the context。
A new direction worth noting: Multi-Intellectual Structures as a scaling strategy for the context itself. If a single model is confined to the 128K token window, a coordinated set of intelligent bodies — each with its own context, a single slice focused on issues, and the results of each other's communications — can approximate the whole infinite work memory. Each smart body does context learning in its own window; systems aggregate. The most recent examples of Karpathy's autoresearch project and Cursor's web browser are early cases. This is a purely non-parametric approach (not changing weights), but it significantly raises the ceiling that the context system can achieve。
Module
In the modular space, teams build embedded knowledge modules (compressed KV caches, adapters layers, external memory storage) to professionalize generic models without retraining. An 8B model with appropriate modules can match the performance of the 109B model on the target task, with memory occupancy only as a fraction. The attraction is that it is compatible with the existing Transformer infrastructure。
Weights
at the end of the weight update, researchers seek true parameter-level learning: updating only the thin memory layers of the relevant parameter segments, optimizing the enhanced learning cycle of the model from feedback, and training in the testing of compression weights in the context of reasoning. these are the deepest and most difficult to deploy, but they allow the model to fully internalize new information or skills。
There are many specific mechanisms for updating the parameters. Some research directions are given:
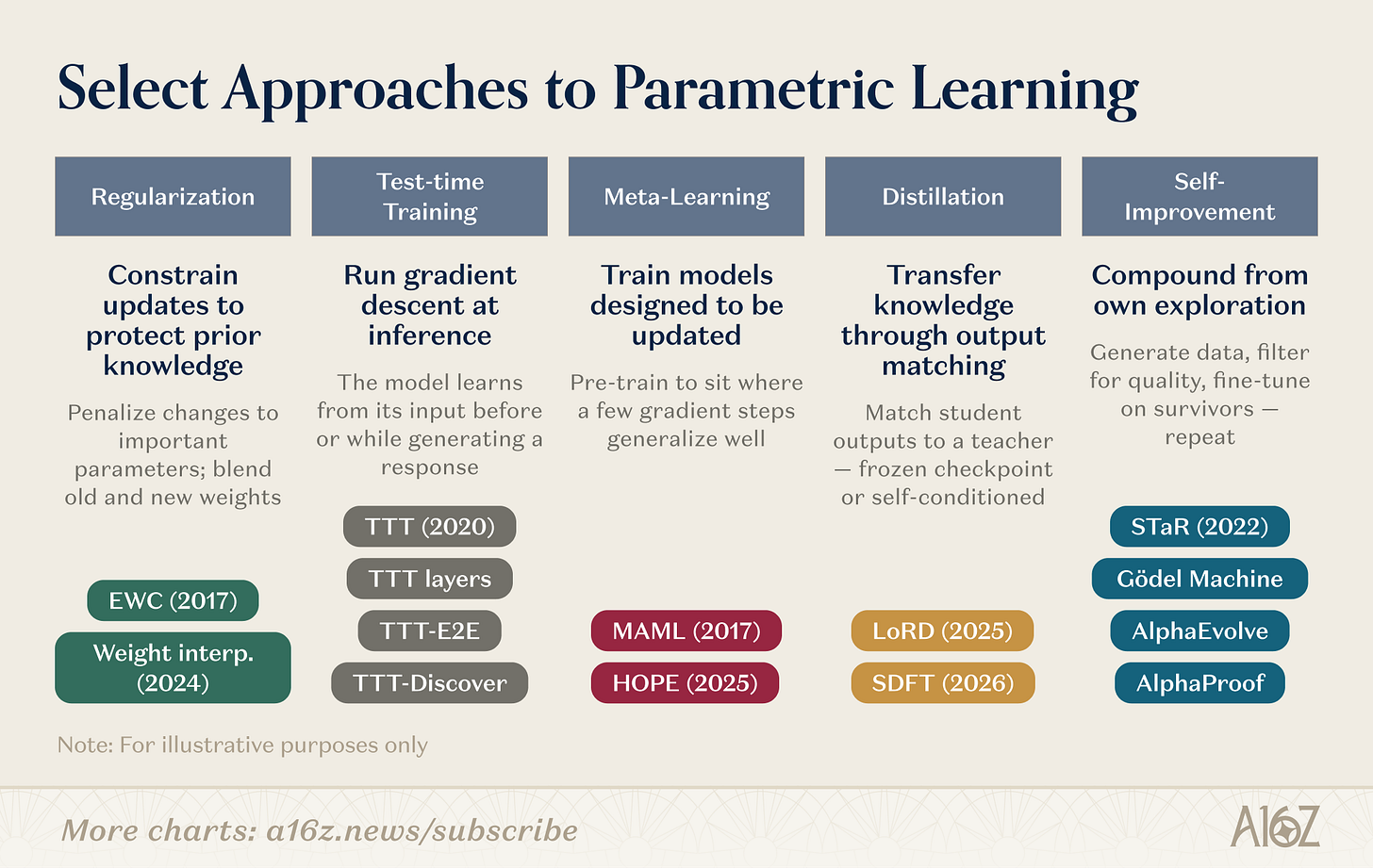
Figure: Overview of research directions for weighting learning
The weighting study covered several parallel routes。Regularization and weighting spatial approachesThe oldest: EWC (Kirkpatrick et al., 2017) punishes parameter changes based on the importance of parameters to previous tasks; weight interposition (Kozal et al., 2024) blends old and new weight configurations in parameter space, but both are vulnerable on a large scale。
Training during testingCreated by Sun et al. (2020), and later developed into the original language of architecture (TTT layers, TTT-E2E, TTT-Discover), the idea is different: to make gradients down on test data and to compress new information into parameters at the moment required。
Yuan learningThe question is: Can we train models to learn how to learn? From the initialization of the few sample-friendly parameters of MAML (Finn et al., 2017) to the embedded learning of Behrouz et al. (Nested Learning, 2025), which structured the model into a layer optimization problem, running fast-adapted and slow-up modules at different time scales, inspired by the consolidation of biological memory。
DistillationKnowledge of previous tasks is maintained by matching student models with frozen teacher checkpoints. LoRD (Liu et al., 2025) allows distillation to operate efficiently to the point where it can be sustained by cutting models and replaying buffer zones simultaneously. Self-distillation (SDFT, Shenfeld et al., 2026) flipped the source, using the model ' s own output under expert conditions as a training signal, bypassing the disastrous memory of the fine-tuning of the sequence。
Recursive self-improvementIt operates on similar lines: STAR (Zelikman et al., 2022) guides reasoning from a self-generated chain of reasoning; AlphaEvolve (DeepMind, 2025) discovers algorithmic optimization that has not been improved for decades; Silver and Sutton's “era of experience” (2025) defines learning of intelligent bodies as a continuous flow of experience that never stops。
These research directions are gathering. TTT-Discover has integrated test training and RL-driven exploration. HOPE embeds a slow learning cycle in a single structure. SDFT turns distillation into a basic operation for self-improvement. The boundary between columns is blurring. The next generation of continuous learning systems is likely to combine strategies: regularization to stabilize, meta-learning to accelerate, and self-improvement to compound gains. A growing number of start-ups are betting on different levels of this technology warehouse。
Continuous learning entrepreneurship
The non-parameter end of the spectrum is most well known. The shell company (Letta, mem0 and Subconscious) builds layers and scaffolds to manage the content of the context window. External storage and RAG infrastructure (e.g. Pinecone, xmemory) provide search backbone. Data exist and the challenge is to put the right slices in front of the model at the right time. As the context window expands, so does the design space of these companies, especially at the outer crust, a wave of new start-ups is emerging to manage increasingly complex context strategies。
Parameters are earlier and more dollars. The company here is trying some version of the "deposition compression" to internalize new information in the weight. The path can be roughly divided into several different bets, about what models should learn after they are published。
Partial compression: you can learn without retraining。Some teams are building embedded knowledge modules (compressed KV caches, adapter layers, external memory storage) to professionalize generic models without moving core weights. The common argument is that you can obtain meaningful compression (not just retrieval), while keeping the balance of stability-plasticity within manageable limits, because learning is segregated, not dispersed across the parameters. The 8B model is accompanied by a suitable module to match the performance of the larger model in the target mission. The advantage is portability: modules can be plugged in with existing Transformer structures, which can be independently exchanged or updated, and the cost of experiments is much lower than the cost of intensive training。
RL AND FEEDBACK CYCLE: LEARNING FROM SIGNALS。Others are betting that the most abundant signal of post-deployment learning already exists in the deployment cycle itself — the signal of reward for user correction, mission success or failure, from real world results. The core idea is that the model should treat each interaction as a potential training signal, not just a request for reasoning. This is highly similar to the way humans progress at work: working, getting feedback, internalizing what works. The engineering challenge is to translate thin, noisy and sometimes confrontational feedback into a stable renewal of weights, without catastrophic oblivion. But a model that truly learns from deployment can yield compound value in ways that the systems below cannot do。
Focus on data: Learning from the right signals。A related but differentiated bet is that bottlenecks are not learning algorithms, but training data and peripheral systems. These teams focus on filtering, generating or synthesizing correct data to drive continuous updating: This presupposes that a model with a high-quality and well-structured learning signal can be meaningfully improved with a much smaller gradient. This is a natural connection with feedback loop companies, but the upstream question is emphasized: whether models can learn is one thing, what they should learn and to what extent。
New architecture: Learning competencies from the bottom。The most radical bet is that the Transformer architecture itself is a bottleneck and that continuous learning requires fundamentally different computational terms: a structure with a continuum of time dynamics and built-in memory mechanisms. The argument here is structural: if you want a system of continuous learning, you should embed learning mechanisms into the bottom infrastructure。

Figure: Business start-ups for continuous learning
all major laboratories are also active in these categories. some are exploring better context management and thinking chain reasoning, some are experimenting with external memory modules or sleep-time computing tubes, and several invisible companies are pursuing new structures. this area is early enough to see that no method has been won and, given the breadth of the case, there should be no single winner。
Why would a simple renewal fail
Updating model parameters in the production environment could trigger a series of failed models that are currently unresolved on a large scale。

Figure: Failed mode of simple weight update
engineering issues are well documented. catastrophe oblivion means that models that are sensitive enough to learn from new data destroy existing manifestations of stability and plasticity. time decomposition means that the same set of weights is compressed by the constant rule and the variable state, and that one update will damage the other. logical integration failed because the updating of facts did not spread to its inference that changes were limited to the token sequence, not the semantic concept. unlearning is still impossible: there is no de minimis operation, so there is no precise surgical removal programme for false or toxic knowledge。
The second category of issues received less attention. The separation of the current training and deployment is not merely an engineering facility; it is a border of security, auditability and governance. Open this boundary, and many things go wrong at the same time. Security alignment may be unpredictablely degraded: even a narrow fine-tuning of benign data may lead to widespread disorders。
Continuous updating has created an offensive face of data poisoning — a slow, lasting infusion of tips, but it lives on weight. Auditability collapses because a continuously updated model is a mobile target that cannot be used for version control, regression testing or one-off authentication. When users interact into parameters, privacy risks increase and sensitive information is baking into the form, making it more difficult to filter than to retrieve information in the context。
These are issues of openness, not fundamental impossibility. Addressing them, like addressing the core architecture challenges, is part of the ongoing learning research agenda。
From memory fragments to real memory
Leonard's tragedy in Memory Fragments is not that he can't operate — he's resourceful and even brilliant in any scenario. His tragedy is that he will never recover. Each experience has stayed outside — a note that was taken, a tattoo, a handwriting of others. He can search, but he can't compress new knowledge。
When Leonard walked through this self-constructed maze, the line between truth and conviction began to blur. His illness is not just a denial of his memoryIt forced him to rebuild his meaningLet him be both a detective and an unreliable teller of his own story。
TODAY'S AI RUNS UNDER THE SAME CONSTRAINTS. WE BUILT VERY POWERFUL RETRIEVAL SYSTEMS: LONGER CONTEXT WINDOWS, MORE INTELLIGENT CASINGS, COORDINATED MULTI-INTELLIGENCE CLUSTERS, AND THEY WORK. HOWEVER, SEARCHING DOES NOT AMOUNT TO LEARNING. A SYSTEM THAT CAN UNCOVER ANY FACTS IS NOT FORCED TO LOOK FOR STRUCTURES. IT WAS NOT FORCED TO BE GENERALIZED. LET SO MUCH TRAINING BE SO DAMAGINGLY COMPRESSED - TURNING RAW DATA INTO TRANSFERABLE REPRESENTATIONAL MECHANISMS - - EXACTLY WHAT WE TURNED OFF AT THE MOMENT OF DEPLOYMENT。
The path forward is likely not to be a single breakthrough, but rather a layered system. Context learning will continue to be the first line of defence: it is original, validated and constantly improved. The modular mechanism could address the middle ground of personalization and specialization in the field。
But for those that are really difficult — hidden knowledge that discovers, adapts, cannot be expressed in words — we may need to let models continue to compress experience into parameters after training. This means progress in thin architecture, meta-learning goals and self-improvement cycles. It may also require a redefinition of what a model means: not a set of fixed weights, but an evolutionary system that includes its memory, its updated algorithm, and its abstract ability from its own experience。
The filing cabinet is growing. But the larger cabinet is the archive cabinet. The breakthrough is the thing that makes models strong when they are deployed and trained: compression, abstraction, learning. We stand at a turning point from memory loss models to models with a light of experience. Otherwise, we'll be stuck in our Memory Debris。
Original Link
