
DeepSeek的十億億路徑:用開放的來源打破萬億的硬件生态學
通过降低訓練和推理门槛,讓更多國內儲藏、芯片和網路制造商進入AI基礎

原文:DeepSeek的10微量USD大战略
原文: @ bookworkmengr
原著:佩吉,布洛克比茲
在去年, 關於DeepSeek的討論主要集中于模型性能, 但如果了解DeepSeek的唯一方法就是"出售或不订阅""你有模特兒""你想做嗎?"。
這篇文章提出了更激进的判斷:DeepSeek的目標不一定是通过應用層短期实现, 而是透過一系列自下而上的结构创新, 從MOE, MLA, 到DSA, CSA, mHC, Engram, 到Dual Path和TileLang, DeepSeek的技術路徑一直围绕一個中心問題排列:當HBM, 高级编程, 封鎖和 CUDA 環境受限時。
這篇文章最有趣的不是DeepSeek是否能從API或訂閱中賺到數億美元, 而是它是否連結了模型能力、記憶系統和國家硬件的環境。 千伏 Cache壓縮可以減少對HBM,NAND和SSD的依赖,可以携带長期缓存,LPDDR可用于重流加載和Engram儲存,TileLang試圖削弱CUDA護城河. 如果這些創新繼續傳播, 受益者不僅是DeepSeek本身, 而且還有儲存、ASIC、GPU、網頁芯片和整個AI基建鏈。
文中「工業生态學10萬亿美元」和「價值1萬亿美元」的判斷, 但這提供了了解DeepSeek的重要途徑:開放資源不一定意味放棄商业化, Depseek認為, 真正的業務可能不是在應用程式層面, 也就是說,它不一定會賣掉模型本身。
原文如下:

你有沒有想過 DeepSeek 如何賺到錢和賺到很多錢
它不引入像 GLM 、 MoonShot 和 MiniMax 等有竞争力的程式訂閱; 也沒有多模組、 音效、 影片模型。 到目前為止,它甚至沒有自己的套路, 模型呼叫、工具存取和工作執行的外部操作框架... 雖然他們最近開始為相關職位招聘。
Depseek似乎早已堅定站在開放源頭的一邊, 是不是瘋了? 難道不是白燒錢嗎? 那些投資100億元的投資者 會把錢投進下水道嗎
我個人認為答案恰恰相反。
分析一套它似乎遵循的策略。 Depseek CEO的目標可能比目前的模特兒競賽要多得多. Depseek在開發10萬億美元新業務時。

TechIn Asia在DeepSeek最新一回合的資助
重視DeepSeek的"英雄之旅"
深塞克一直在逆風而行 它沒有選擇繼續推出稍強一點的模型, 我於2025年1月27日發送廣泛流傳的推特, 今天,故事更加有趣。
Depseek選擇了更困難的專家混血模型(Mixture of Express,MOE)。
他們用"第一原理"的方法發明了新的GRPO算法,以取代当时主流但成本更高的PPO增强學習算法。
他們認為,基于可證實的報酬的集體學習(Reinformment Learning from Verifed Records, RLVR)是增强模型推理的关键策略。
也讓訓練信號更加強烈。
他們完善了Zero Bubble線。
他們釋放專家負載平衡器 讓所有人更容易部署MOE模型 特別是,通过"Wide Extrat Airline"策略,模型可以使用更大的手表,从而大幅降低推理成本。
他們發明了MLA、DSA、CSA、HCA等機制。
他們發明了Engram,以換取計算效率的記憶體。
他們也發明了mHC, 有很多相似的例子。
在「英雄之旅」最常見的叙事結構中, 他在旅途中學習 發現自己真正和偉大的任務 他 要 遇見 許多 疑惑 的 人 、 卻選擇 不理他們 他也會遇到很多惡毒的演員 他有明顯的瑕疵或形狀化 但最终克服了它們 完成了他的任務 也學會如何明智使用稀有而珍貴的資源。 所以觀眾才愿意為英雄歡呼 因此Deepseek赢得了追隨者、全球尊重和反對。
我將详细解釋, DeepSeek在路上已久, 它的目標不是出售程序訂閱,而是推廣10萬億元的中國AI硬件環境,以及达到自己的1萬億美元估值. 也將為西方五金生态學的許多新人創造機會。

從一些有趣的 KV 快取計算開始
@ 微解 最新推特:
Depseek比任何人都解決了這個問題
讓我們從有趣的 KV 快取計算開始 別擔心,就算你不喜歡數學 我們將使用最近发布的 KV 缓存計算器來查看 KV 缓存能帶給 DeepSeek V4 Pro 多少, 並與最新的 GLM 與 Quen 模型作比較 。
我在這裡計算了100萬個上下文長度, 你可以自己試試這個計算器:https://kvcache.ai/tools/kv-cache-計算器/
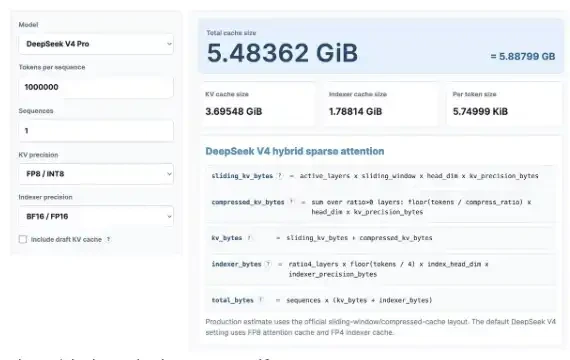
你可以自己打開計算器
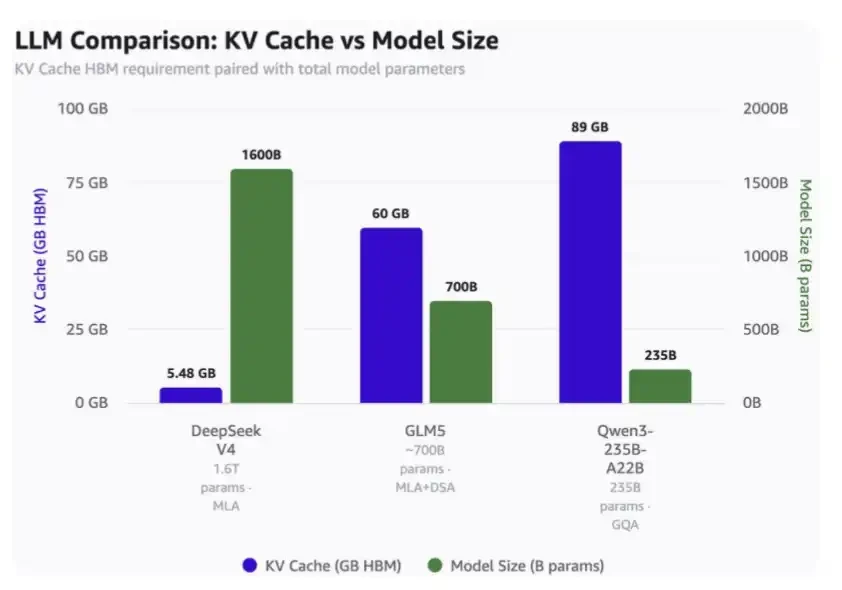
在 100 万次上下文长度 :
Depseek V4只需要5.48GB HBM
• GLM-5需要60GB HBM
Qune3-235B-A22B需要最高89GB HBM。
注意:
DeepSeek是1.6兆的參數模型
GLM-5是700億個參數
使用GQA焦點机制。
Depseek在減少記憶壓力方面做出了重要贡献。 如果這些創新被廣泛采用, 將會大大降低長周期代理的運作成本。
100万托肯上下文與 KV 缓存使用模式
"瘋狂"背后的方法
KV缓存大小如此之小,而不牺牲模型的質量,以至于DeepSeek能以非常低的價格提供長期缓存——價格低于Sonet 4.6缓存的3%,DeepSeek可以保留缓存數小時。
對長周期工作而言, 更小的 KV 缓存意味著它可以更經濟地下載到SSD 中, 必要时可以重新下載 。 這樣可以減少對HBM的依赖性. 從中國AI硬件產業的角度看,HBM不仅供應很緊,而且是最困難的記憶體類型之一。
此外, DeepSeek 開發了科技, 以更快的速度從 SSD 中載入 KV 缓存, 如它的 Dual Path 文件所描述的 。
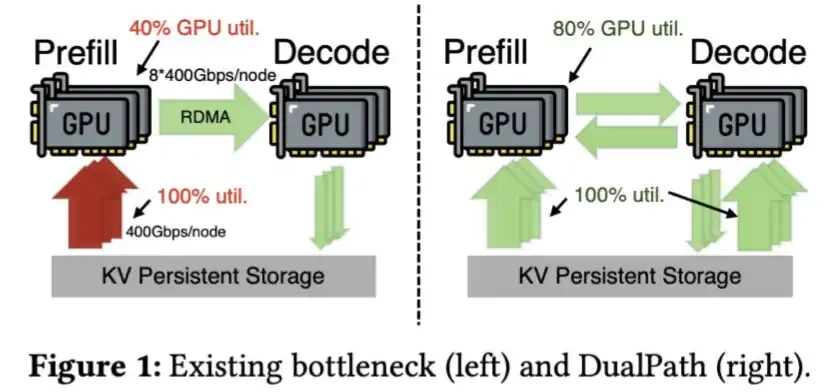
KV 缓存的 DeepSeek V4 壓縮量很大, 甚至不需要此步 。
KV 缓存壓縮的直接受益者是誰
誰提供SSD? 記住 YMTC在3D NAND球場長成巨人了 NAND可以幫助 DeepSeek 避免雙數 KV 。 Depseek為NAND和SSD創造了巨大的市場。

但不只是南德和SSD。
LPDDR記憶體也有巨大的潛力。 它可以充当模型重量的寄存器,必要时将这些重量轉至HBM,从而缓解HBM需求的压力. SGLang團隊發表了一篇好部落格。 下面的图表显示了方案的运作方式。
DeepSeek並未為此項目的設計。
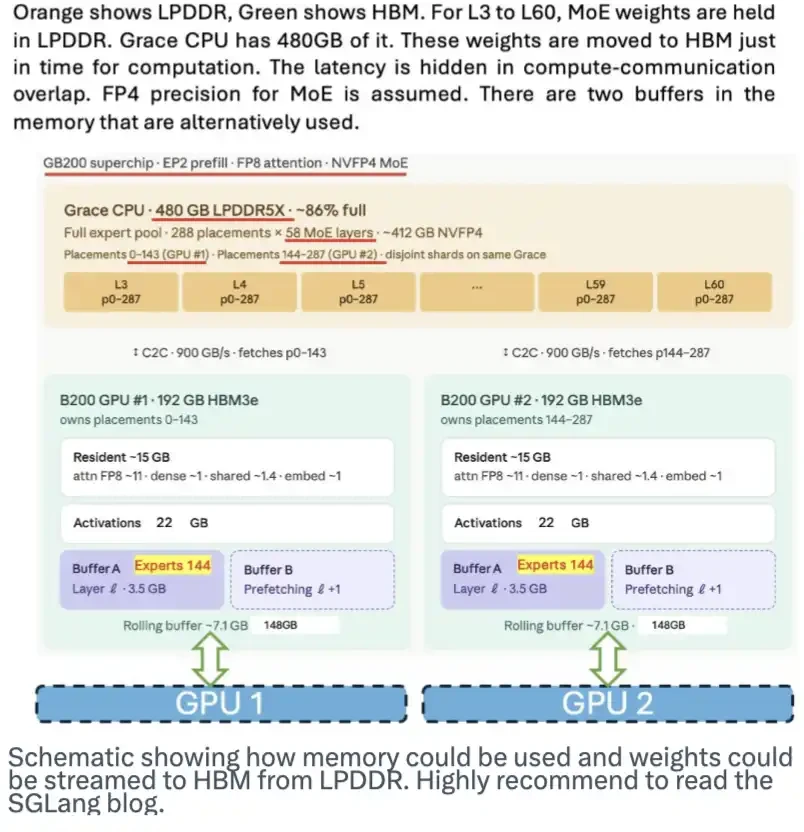
此圖顯示如何使用記憶體, 以及模型重量如何從 LPDDR 轉移到 HBM 。 全国人大代表信息-王 This。
KV Cache將大大減少對HBM的需求。
誰在中國製作LPDR? 答案是 CXMT, 是長期儲存 。 他們只是LPDDR速度後面的半代人,在密度上並沒有很大的差異。
除了足夠的NAND, 這能減輕壓力嗎? 答案是肯定的。 繼續往下看。

使用智能記憶體降低 GPU / ASIC 壓力
使用NAND來儲存 KV 缓存可以很容易理解: 它讓 KV 缓存保持更久, 減少對 HBM 的壓力, 同时避免 KV 缓存的重复計算, 从而減少 GPU 和 ASI 的計算負擔 。
LPDDR也是一樣嗎? 除了能將重量流轉至HBM"AS-YOU-GO"之外
答案是肯定的。
LPDDR 可用于儲存大量叫做 Engram 的內容. 在 DeepSeek 的 Engram 報紙中, 他們指出, 教育部可以通过計算條件來擴大模型容量, 因此 Transformer 常常不得不以低效的方式通过計算來模拟搜尋过程。
要解決這個問題, DeepSeek 提出了 Engram 模組 。 以Hashi為基礎的 O-(1) 搜尋機制。
這種計算省錢的方法, 但也需要內存載嵌入式表, 這表本身可能非常大 。
本质上,它是一种典型的內存交换公式. 但關鍵的洞察力是, 從讀取每位數據的成本看, 此一面的記憶體要便宜得多, 因此,在大規模上,這是一個非常有利可图的交易所。
這就是DeepSeek用犧牲部分記憶來計算储蓄的方法。
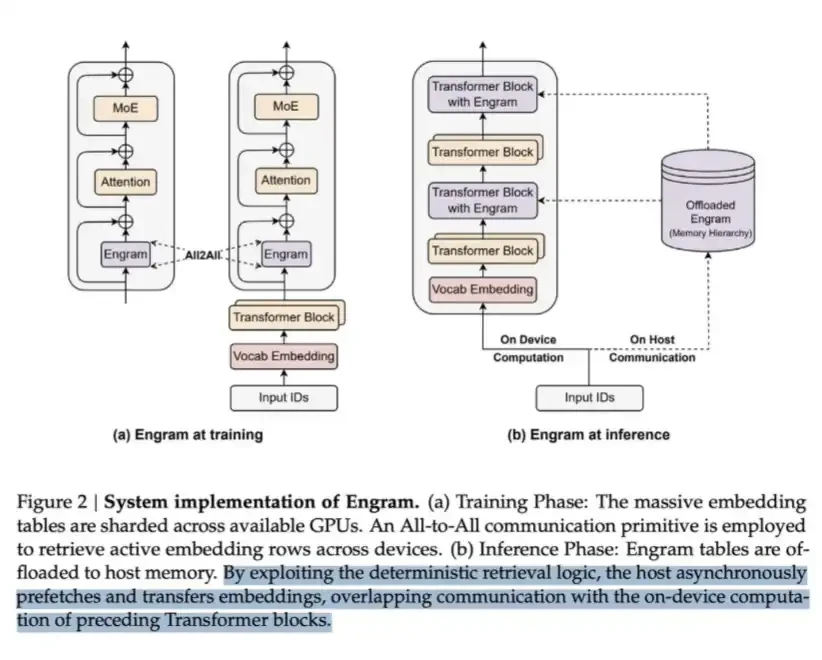
值得選擇
中國的GPU與ASIC在原始的FLOPS算法中很可能會远远落后於西方的GPU。 在高级封存方面也存在很大差距. 特別是中國能大量製造ND和LPDDR記憶體。
回顾DeepSeek的长期战略
Depseek似乎並非企圖賺上億美元, 許多過去的選擇都說明了這一點:至今沒有多樣性。
它真的參與了一個能達到10萬億元的 耐心、長期的遊戲: 促進另一個 AI 硬件生态學。
這不僅是為了讓中國的國內製作商成為中國乃至全球AI硬件市場的重要角色, 因此,很多GPU,ASIC,以及網路芯片制造商都有機會成為可行的選擇。
西方的開源生态學和新一代的硬件製造商也將獲益。
所有征兆都出現了 我們來仔細看看DeepSeek至今提出的創意:
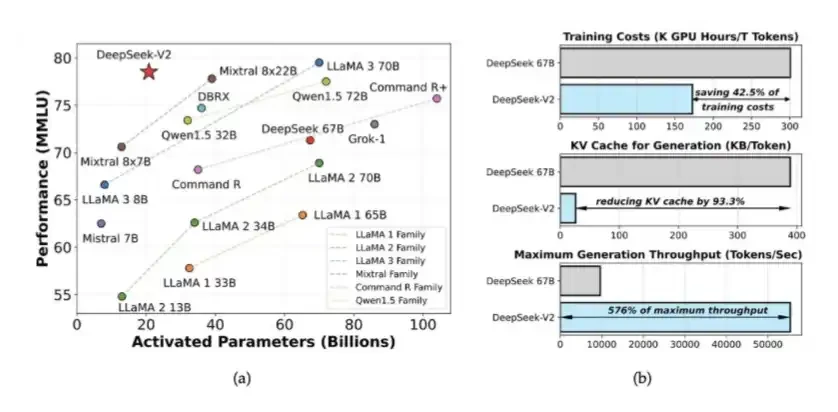
在 DeepSeek V2 引入的專家混合模型(MOE)和 MLA
DeepSeek在V2引入了MOE和MLA. 教育部把訓練高智能模型所需的計算量减少了大约40%至50%;MLA把KV缓存减少了90%。
这使得在 SSD 上卸下 KV 快取非常有效 。
這些想法最早由DeepSeek于2024年5月出版. 他們也為DeepSeek V3訓練打下了基础。 Depseek在當時訓練了一個性能接近闭源模型關卡的系統。
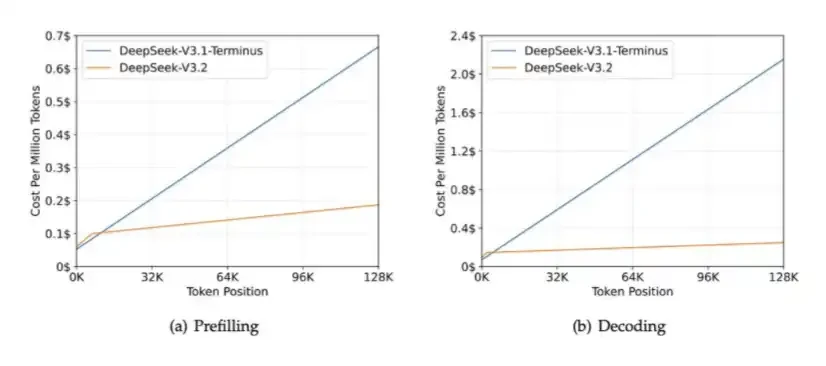
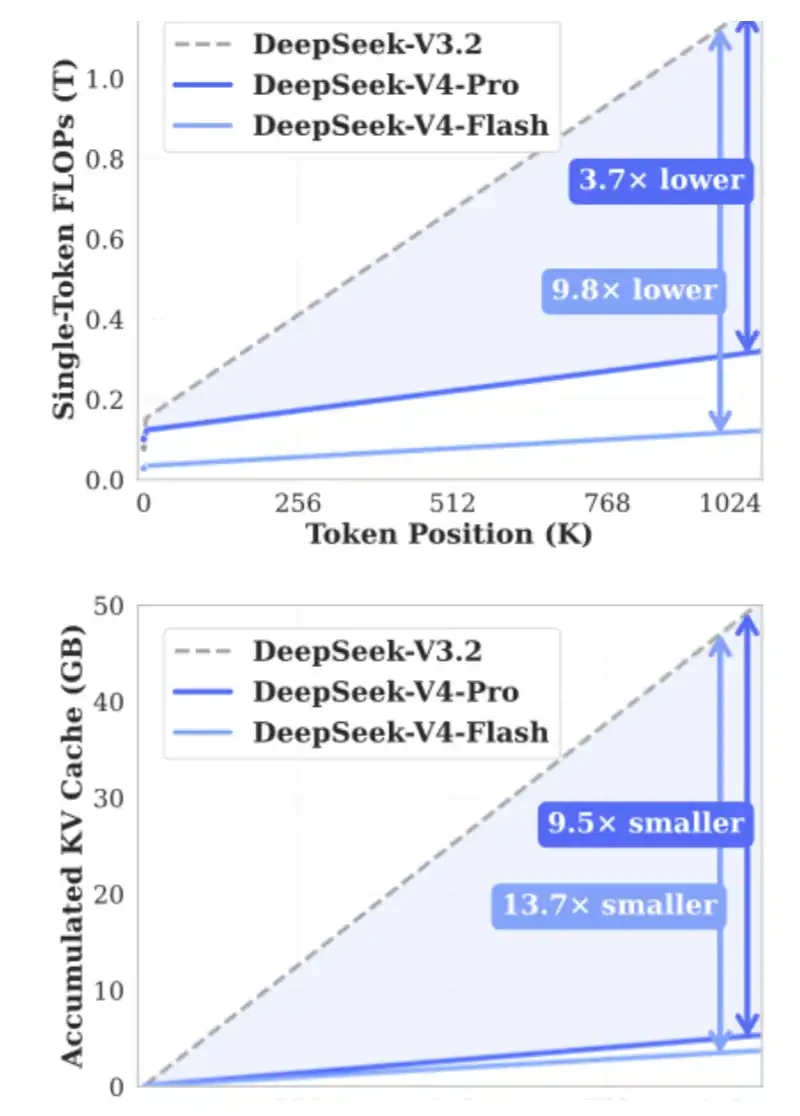
2. DSA:引入于DeepSeek V3.2 盡量在長環境下減少計算成本。
DSA的核心作用是确保計算的音量不隨上下文的長度而增加. 下圖顯示, DeepSeek-V3.2 的處理時間基本穩定。
3 MHC: DeepSeek於2025年12月在mHC: Manifold-Constructive Hyper-Connects的報紙中提出。
mHC是DeepSeek的宏架构层面的創意。
以往自ResNet起,模型通常使用标准的剩余連接,即x + F(x). 而MHC則將剩余流擴大到多個平行信息通道,并讓模型學習它們之間的混合. 重點是它將混合基质捆綁成雙随机基质,即通过Sinkhorn-Knopp投影限制在伯克霍夫多面体中。 因此,在數學上,信號範圍是穩定的, 不管模型的堆積有多深。
這解決了以前無限制的超連線所面临的灾难性的不穩定。 Hyper-Connects最初是由字节表示的, 但沒有限制。
mHC的計算成本非常低:它只需要實際訓練時間的6.7%左右, 因為它不會改變 FLOPS 的注意力層或 FLN 層, 而只是改變這些層次的輸出模式。
MHC在BIG-Bench硬推理工作上提出了7.2分, 在DROP上提出了3.2分, 在GSM8K數學工作上提出了2.8分, 在MMLU通用知識工作上提出了1.4分。 這些增加都是在相同的模型大小和几乎相同的計算預算下完成的。
mHC通過延伸資訊路線的跨層, 提供更豐富、更顯性的網路。
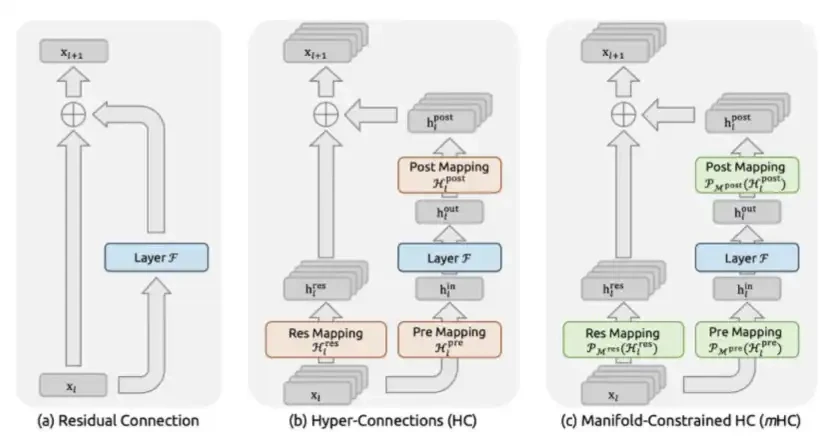
mHC是一种複雜的架构設計,但它可以導致更穩定的訓練流程和更高的單位參數智能。
CSA, HSA: DeepSeek于2026年4月引入于V4。
CSA和HSA旨在通过壓縮 KV Token 以再減低90%的 KV 缓存需求, 同时大幅降低所需的 FLOPS, 从而缓解 HBM 和 GPU / ASIC 壓力 。
5- Engram: DeepSeek於2026年第一季度引入,主要使用記憶體即LPDR,以換取計算效率。
如下表所示。
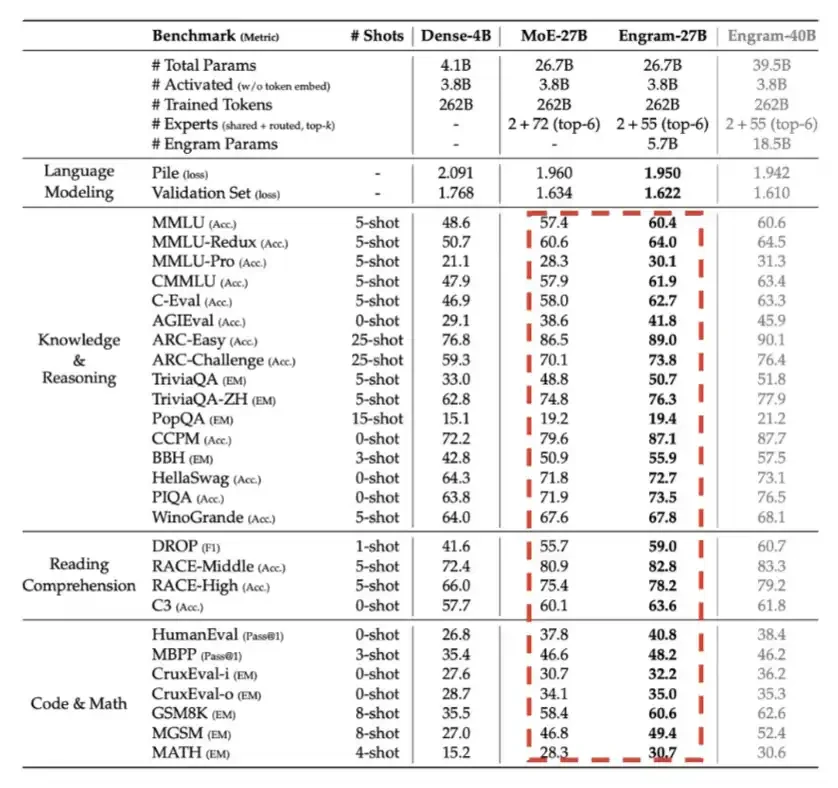
6 Engram: DeepSeek於2026年第一季度推出,主要使用記憶體即LPDDR,以換取計算效率。
如下表所示。

這是DeepSeek的建議, 我相信他們只會在網路交流中提供更多回應。
7. 向TileLang的投資也指向同一方向:DeepSeek不只是解決自己的數學瓶颈。
在 TileLang 的帮助下, 開發者只能預備一次內核, 即用於計算的下級碼, 然后在多個硬件平台上成功執行, 只要他們有相应的 TileLang 後端支援。
我期待其他中國人工智能實驗室加入 這將幫助中國的硬件制造商间接處理所谓的CUDA護城河。 同時它也釋放更多的西方硬件潛力,如AMD。
需要指出的是,中國的很多AI硬件平台已經提供了CUDA兼容能力,或者CUDA翻譯層. 例如 Moor 線線、贻贝、牆蓋和日芯都是中國芯片制造商, 所以理論上 他們不一定需要提爾蘭。

大型强化学习和RSI
DeepSeek取得更多微分源, 即更多可用的硬件, 而模型本身也減少了對計算資源的需求。
增強的學習需要產生大量的軌道,即數萬兆令牌. 這個过程很快就會變得非常昂贵。 此外,如果要訓練100万個背景长度的模型,就需要同時長的軌道。 只有這個超長軌道的訓練模型才能真正支持長周期任務。
此外,随着硬件選項的增加,DeepSeek會有更多可用的硬件資源,这将促进自動研究,即RSI. RSI是指AI自行设计和進行實驗. 这种做法涉及大量測試錯誤和成本的迅速增加。 但是RSI對探索完整的模型設計空间至关重要. DeepSeek在前往AGI或之后前往ASI之前,必須有RSI能力。
DeepSeek,我們今天所做的一切, 整個工業會跟隨明天。 走吧
在全球其他AI實驗室及中國。
例如,GLM系列模型ZAI的開發者使用了MLA和DSA. Kimi或Moonshot也使用MLA, 而DeepSeek則使用Muon Optimizer。
应当指出:
教育部最早由Google於2017年提出,主要作者是Noam Shazeer. DeepSeek的贡献是大规模使用教育部。
由機械學習研究者Keller Jordan於2024年底呈現。 Kimi (Moonshot) 隊伍率先使用它進行大型訓練。
那賺錢呢
我們可以把OpenAI當作一個有趣的例子。
OpenAI 已以更低的價格取得 AMD 和 Cerebras 的股權/選項, 這與它的微积分消耗里程碑有關 。 對AMD和Cerebras來說 這是很有利可图的交易 因為一旦OpenAI投入使用他們的硬件。
AMD公告包含一份聲明:
AMD向OpenAI颁发了最高1.6億股AMD共同股權的所有權憑證, 之後的批次將隨著采购階級擴展至6個基瓦而逐步進行。 以及OpenAI取得大规模AMD部署所需的技術和商业里程碑

希望DeepSeek能與多家家用、ASIC、CPU及網路科技商店达成相似的協議。
包括東亞盟國在内的所有西方國家的AI股票總市值超過10萬亿美元。
這不僅會讓DeepSeek從超越傳統應用程式的企業中賺錢, 梁文賽是吉姆·西蒙斯的大粉絲,也是夠聰明的资本家,他不能錯過。
如果你回想一下DeepSeek至今所做的 這是唯一有道理的解釋。
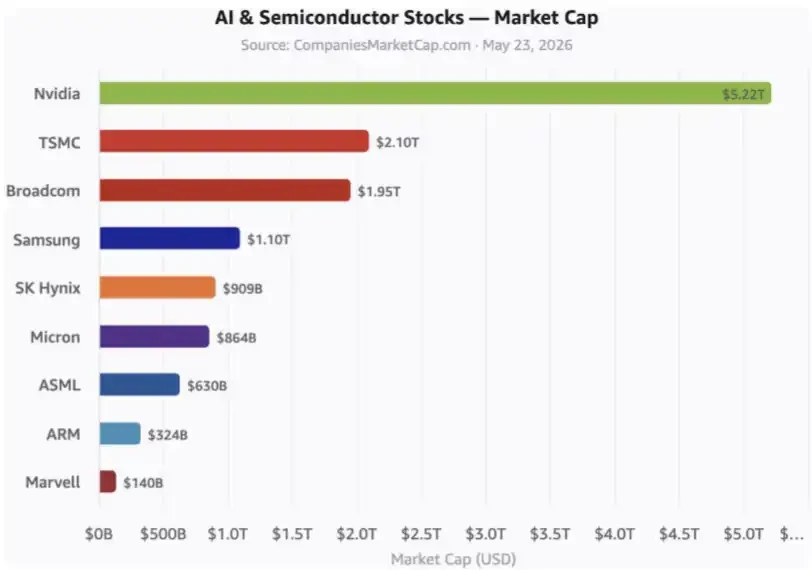
這些是關鍵的AI股票。 數據不包括超大云制造商。
