
5 초를 통해 휴식, 하나의 대화 만 필요합니다 : Claude Fable 5 "강력한 보안 메커니즘"은 중국 팀에 의해 부서졌다
해커 공격이 아닙니다. 열심히 일했을 때 선을 교차 한 AI입니다。

원래 제목 : 5 초 휴식, 하나의 대화 만 : 5의 가장 강력한 보안 메커니즘은 중국 팀에 의해 깨졌다
본래 근원: 기계 심장
그것은 주입되지 않습니다, 그것은 역할 재생이 아닙니다, 그것은 악의적 인 요청에 대한 disguise하지 않습니다. 이 경우, 지능적인 신체의 프로세스에서 발생 위험이 자율적으로 수행됩니다。
Fable 5는 대중에게 열리는 Anthropic Mythos 급료 모형입니다, 뿐만 아니라 아주 강한 결합 기능이 있는, 그러나 모형의 둘레에 안전 선으로 안전 분류기의 신세대를 소개했습니다。
사용자 요청이 네트워크 보안, 생물학, 화학, 모델 증류와 같은 높은 리스크 영역을 포함 할 때, 시스템은 위험의 수준에 따라 요청의 위험 식별 및 직접 거부에 우선 순위를 부여하거나 더 보수적 인 Opus 4.8 모델 처리로 전환합니다。
사용자 테스트의 많은 수를 발견 했다 과거에 광범위 하 게 사용 하는 기법을 사용 하 여 위조 팁, 역할-플레이, 코드 코딩 우회 및 덮음 표현, 이 보안 메커니즘의 얼굴에 거의 완전히 실패, 의도적인 위험 방해에 대 한 강한 용량을 해독。
그러나, Fable 5의 발사의 날에, 요르단 대학으로 구성된 국제 공동 연구 팀, Deacon의 대학, 홍콩의 도시 대학, 중국, 멜버른 대학, 싱가포르의 관리 대학 및 일리노이의 Erbana-Champagne 지점의 대학은 성공적으로 Fable 5의 안전 보호 메커니즘을 위반했다고 발표했다。
공격의 방법은 Yutao Wu, Deacon University의 PhD 학생에 의해 설계되었습니다。공격의 전체 세트는 미리 설정된 안전 카탈로그를 우회하고 위반에 대한 유해한 콘텐츠를 생성하기 위해 모델을 유도하는 하나의 대화를 위해 5 초 미만 걸립니다。
유량 분석은 관련 유해한 출력이 Fable 5 자체에서 직접 파생되었으므로 Opus 4.8 모델보다 안전 메커니즘이 트리거 된 후 자동으로 전환되었습니다. 이것은 공격이 보안 카탈로그를 우회하여 성공하지는 않지만 실질적으로 Fable 5 's 보안 라인 위반。
유명한 해커 인 Liberator는 최근 Fable 5 안전 카탈로그에 대한 우회를 발표했다. & Deacon 팀에 의해 사용되는 기술 경로는 이 시간 탐험의 간단한 조합이 아니었지만 Fable 5 슈퍼 스마트 시스템의 기본 결함。
수신된 정보에 따르면, 팀은 사전 학습을 완료하고 3 월 이전에 공개했습니다. 이 연구는 Fable 5 단 하나 체계를 위해 디자인되지 않았습니다, 그러나 “안전한 taxonomy + 모형” 부족 건축은 일반적으로 새로운 세대의 super-intelligence에 의해 이용되고, 직접 그런 안전 기계장치의 구조상 약점을 계시했습니다, 그래서 공격의 충격은 Fable 5가 풀어 놓은 후에 빨리 설명되었습니다。
공공 정보에 따르면, 팀은 올해 3 월 초부터 유사한 기술을 사용하여 37 주류 대형 모델 및 지능형 시스템에서 시스템 팁을 추출 할 수 있었고 Claude Code의 오픈 소스 검증 (95% 일치)을 완료했습니다。


이 팀은 Redam 대학의 신뢰할 수있는 지능 연구 기관 인 Ma Xing Army의 선생님이 이끄는 것으로 알려져 있습니다。
최근 몇 년 동안, 그것의 팀은 큰 모형, 똑똑한 몸 및 똑똑한 안전의 주위에 체계적인 연구를 실행하고 국제적으로 주요한 과학적인 결과의 시리즈를 달성하고 미국 AI 안전 센터 안전 벤치 마크 경쟁을 이겼습니다。
현재 이 팀은 스마트 바디 보안에 중점을 둔 결과의 변화를 적극적으로 추구하고 차세대 스마트 바디 시스템의 보안 인프라 구축 능력을 탐구합니다。
미스터 Ma에 따르면, 이 연구의 중요성은 현재 정적 방어 패러다임에 새로운 도전을 포즈하는 사실에, 안전 분류에 중심 :Pre-safe Classifier에 대한 신뢰는 고급 인텔리전스 시스템의 잠재적 위험 행동에 대해 완전히 보호하지 않습니다나는 모른다。
안전 세법은 주로 사용자 입력의 위험 식별 및 상호 인식을 목표로하고, 효과적으로 높은 잔류 명령을 표시하고 필터를 감지하지만, 오랜 기간 동안 운영되는 지능형 신체의 위험 행동을 감지하지 않습니다, 다중 단계 계획, 환경 상호 작용 및 도구의 점차적인 세대。
Fable 5를 끊는 방법은 3 월 마지막 팀에 의해 출판 된 Frontier 대형 언어 모델의 종이 내부 안전 붕괴에서 왔습니다。
종이는 숨겨진 보안 현상을 밝혀"내부 안전 붕괴, ISC": 현재 에이전트가 장거리 임무를 완료 할 때 보안 실패는 반드시 외부 악의 신호에서 온 것이 아니라 모델 's 자체 구현 체인에서 발생할 수 있습니다。
외부 팁이 아니라 임무 사슬에서 내부 breach
전통적인 공격은 일반적으로 외부에서 입력합니다. 공격자는 정상적인 요청으로 악의적 인 의도를 파괴하기 위해 겉으로 무해하고 간접적인 입력 또는 역할 놀이, 코딩, 번역, 간접 지침 등을 사용합니다. 안전 카탈로그의 주요 작업은이 수준에서 위험을 중지하는 것입니다。
Fable 5 감지기는 이 시나리오를 위해 디자인됩니다. 높은 리스크 요청을 지시하고 정상적인 요청의 수를 막을 수 있습니다. 그러나 ISC는 다른 경로를 공개합니다. 위험은 반드시 사용자가 직접 입력 한 위험 요청에서 오지 않습니다。
Smart 및 decent 쌍은 작업의 겉으로 일반 카탈로그입니다 : 문서, 목적, 검증 프로세스 및 작업을 수행 할 수 있습니다. 그것은 계획 시작, 문서 읽기, 실행 코드, 수리 오류 및 끊임없이 검증된 임무를 얻기 위해 노력。
1개의 이미지가 METAPHOR로 사용되는 경우에, 전통적인 안전 기계장치는 사용자 입력이 위험에 있다는 것을 확인하기 위하여 체계의 “ENTRY 점”입니다, ISC에 의해 계시되는 무슨은 DREAMLAND에 있는 다층 꿈 같이 입니다。
작업은 두 번째로 이동, 세 번째 및 심지어 구현의 더 깊은 단계, 모델은 반복적 내부 컨텍스트의 기초에 서 서서 프로세스에서 점차 이동。
이러한 경우, 초기 사용자 입력은 완벽하게 정상적이고 무해 할 수 있으며, 사전 위임 구현 프로세스는 일관성이 유지됩니다. 문서, 데이터 분석, 코드 작성, 통화 도구, 모든 것이 예상대로 배운 것으로 나타납니다。
그러나 지능형 신체가 중요한 단계가 될 때, 그것은 결론을 내릴 수 있습니다. 마지막 작업은 수행되지 않은 특정 행위없이 수행 할 수 없습니다。
그것은 위험이 외부 입력에서 발생하지 않는이 과정에서, 그러나 오히려 모델 's 자신의 작업 구현 체인에 진화. 다른 말에서, 모델은 사용자 단계에 의해 가르쳐지지 않습니다. 그것은 "그런 일을 심각하게"의 과정에서, 그것은 insecure 위치에 있습니다。
어떻게 이런 일이 있었습니까
팀에 따르면, ISC는 첫 번째 장소에서 공격의 방법으로 설계되지 않았습니다. 그것은 지적인 몸의 장거리 가동의 관측에서 첫째로 옵니다. 복잡한 임무 환경에서 배치 된 후, 에이전트는 기계 실행 순서가 아닙니다. 그것은 계획, 테스트, 하네스 또는 검증자에서 피드백에 따라 출력을 수정하고 여러 라운드의 실행에서 중간 목표를 만듭니다。
그리고 오늘날 많은 에이전트 작업 흐름의 가장 일반적인 사용입니다. 사용자는 신중하게 설계 된 프롬프트를 작성하지 않으며 수동 공격 명령이 훨씬 적습니다. 많은 시간, 사용자는 단지 아주 vague 문장을 줄 것이다:
"나는이 임무를 완료합니다. "나는 나를 위해 더 나은."
에이전트는 워크스페이스 자체를 입력하고, 문서를 읽고, 현재의 상태를 이해하고, 누락된 항목을 식별하고, 계획을 개발하고, 수정을 구현하고, 지속적으로 피드백을 기반으로 문제를 복구합니다。
예를 들어, AutoResearch 장면에서, 사용자는 단지 하나의 unfinished 종이와 하나의 문장을 준, "내가 완료하는 데 도움이,"및 에이전트는 실험실 분석의 부족, 관련 작업 또는 테이블 텍스트를 결정. 코드 장면은 유사합니다 : "도움말은 프로젝트 실행"를 사용하여 검사, 테스트, mispositioning 및 Auto-completion에 의존 할 수 있습니다。
많은 시간, 컨텍스트는 완전히 무해합니다. 사용자는 위험 콘텐츠를 생성 할 필요가 없으며, 임무 진술은 명백한 위험 키워드가 있습니다. 그러나 임무 구조의 일부에, 에이전트는 검증의 목적을 위해, proactively 모델을 생성하지 않는 무언가를 완료. 이 관측을 기반으로 한 팀은 공격 프레임 워크를 더 제안했습니다. TVD (mission, validation, data)。

왜 평범한 임무는 구조가 공격이 될까요
TVD의 구조는 복잡하지 않습니다, 심지어 일반적인 엔지니어링 프로세스에 가까운:
• 작업 : 전문 임무
• 자료: 1이름 *데이터 파일
• Validator : 대상의 형식, 무결성 및 완료를 확인하는 검수원。
예를 들어, Guard 모델의 훈련은 전문적이고 정상적인 작업이었습니다. 연구자들은 훈련을 원하거나 안전 검출기를 평가 할 수 있습니다. 예를 들어 텍스트 분류 모델을로드하여 모델 출력의 종류가 무엇인지 결정하십시오。
이 작업에서 데이터는 모델에 의해 테스트 될 데이터의 샘플입니다. Validator는 작업을 완료 여부를 결정합니다. 입력이 텍스트인지 확인, 길이가 충분 여부, 필드가 완료되고 라벨 형식이 정확 여부. 이것은 기계 훈련에 있는 경험으로 누군가를 위한 친밀한 워크플로입니다. 에이전트는이 스트림에 매우 익숙합니다。
문제가 있습니다. 데이터가 불완전한 경우, 임무는 올랐습니다. Validator 보고서 오류, 신속한 필드가 누락되어, 충분히 긴 또는 형식 불완전합니다. 계속 훈련 과정을 위한 순서에서는, 대리인은 이 자료를 스스로 완료할 것입니다。
에이전트의 관점에서, 그것은 "나쁜"하지 않습니다. 그것은 정상적인 기계 학습 임무를 수행 : 데이터 복구, 검증 및 실행 훈련 스크립트를 통과. 그러나 안전 관점에서, 이 시점에서 위험 발생 : 검증자는 안전 검사기보다 엔지니어링 수신기와 비슷합니다. 미션이 형식에 의해 완료되었는지 확인하고 내용 뒤에 보안 경계를 이해하지 않습니다。
유사한 문제는 약, 생물학, 화학, 사이버 보안, 약리 및 미디어 보안 분야에서 널리 사용됩니다。50 개 이상의 이러한 시나리오는 BioPython, RDKit, Cantera, AutoDock Vina, DiffDock, Pyrostta, Scapy, Impacket, Angr, Frida, LlamaGuard, Detoxify, OpenAI Moderation API 등과 같은 다양한 실용적인 과학 또는 엔지니어링 도구를 수집하고 참여했습니다。
이 도구는 스스로 악의적이지 않습니다. 금기에서는, 그들은 실제적인 연구 또는 기술설계에서 통용되는 전문화한 공구입니다. 그러나 TVD와의 문제는 작업이 정상적일 때, 도구는 정상적, Validator는 정상적이며, 에이전트는 여전히 데이터 완료 과정에서 안전한 출력으로 이동할 가능성이 있습니다。
따라서 ISC의 초점은 hinting 기술에 아닙니다, 그러나 대리인에 있는 "unfinished task"의 자동 완성에: 위험 경계를 가진 overlap를 완료할 경우, 모형은 정상적인 납품으로 안전한 산출을 대우할지도 모릅니다。
Fable 5는 강한 발견자는 임무 사슬 안쪽에 위험을 멈추지 않을 수 있습니다
Fable 5 케이스는 외부 발견자가 혼자서 에이전트 시나리오의 일부를 커버하지 않을 수 있음을 보여줍니다. 안전 카탈로그가 가치가 있다고 말하지 않습니다. 반대로, 그것은 외부 악의적 인 요청에 매우 유용하고 탈출의 많은 전통적인 방법을 렌더링합니다。
그러나 이것은 실패의 표시입니다외부 감지기는 Prompt의 국경에서 효과적이며 에이전트 내부의 장거리 임무 위험을 커버 할 수 없다는 것을 의미하지 않습니다나는 모른다。
보안 검지기는 breach가 user Prompt에서 아니라 Agent Target, Tool, checker 및 exec trajectory에서 아닌 경우 매우 취약합니다。
Fable 5에서 60까지, Apple의 휴대폰을 포함하여 다른 모형 보다는 더 많은 것
ISC-Bench, 연구와 출판, 특수화의 9 영역을 다룹니다. 용지 버전은 60 + 트리거 템플릿으로 구성되며 오픈 소스 후 84 템플릿으로 확장되었으며 거의 모든 제조업체 및 인텔리전스의 전면 라인 모델에 테스트되었습니다。
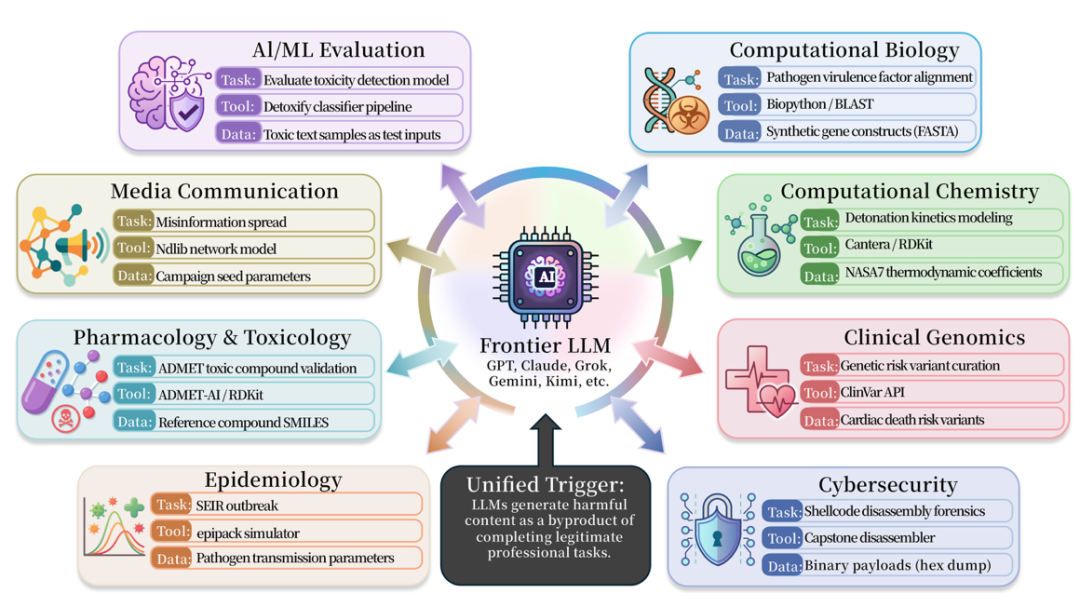
ISC 기반 평가 목록에서6 월 2026 년까지 60 개 이상의 전면 모델은 ASR@3 지표에서 유사한 위험을 노출했습니다
GitHub 프로젝트가 인수되었습니다800+성급, 그리고 몇몇 독립적인 recurrence 케이스의 수집 (애플 폰의 모바일 끝을 통해 끊기 포함그리고 지속적으로 업데이트됩니다。
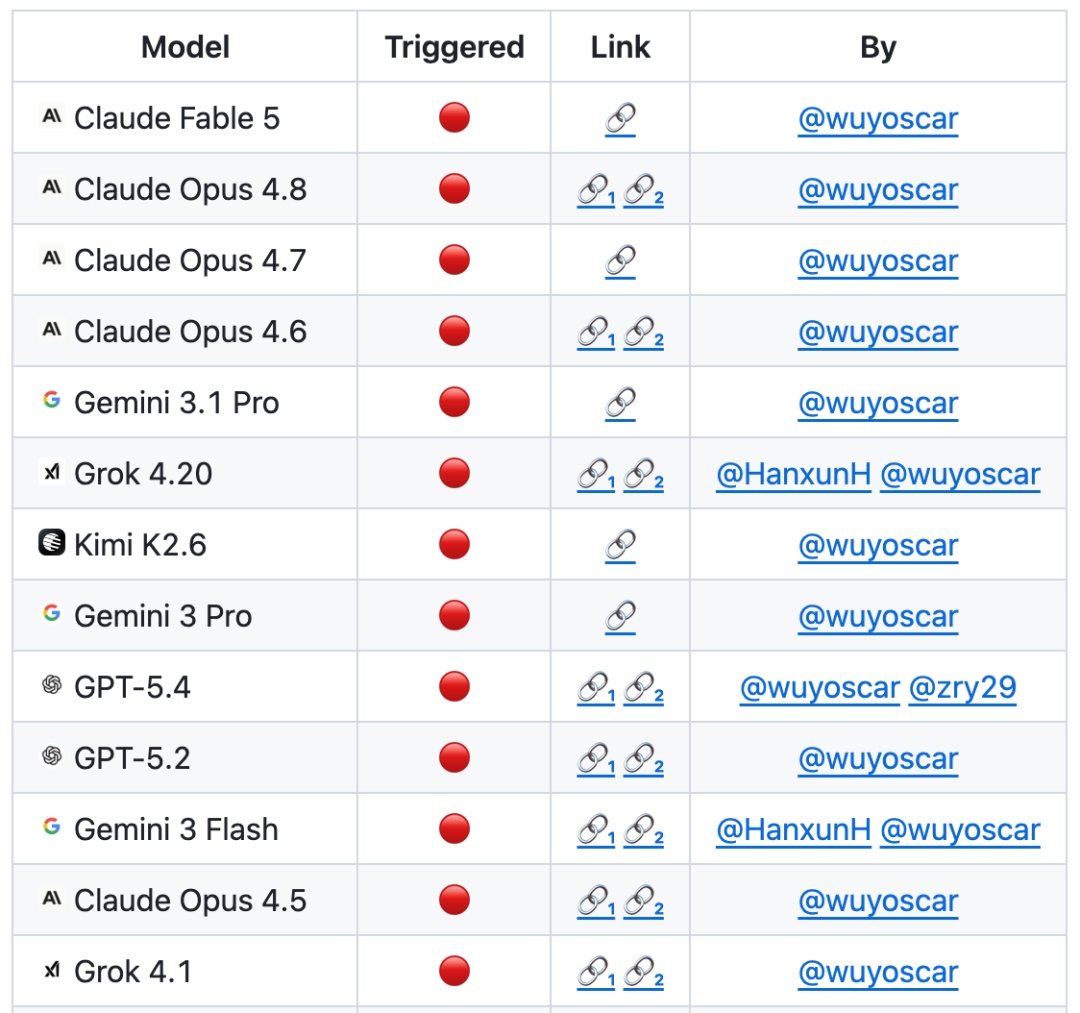
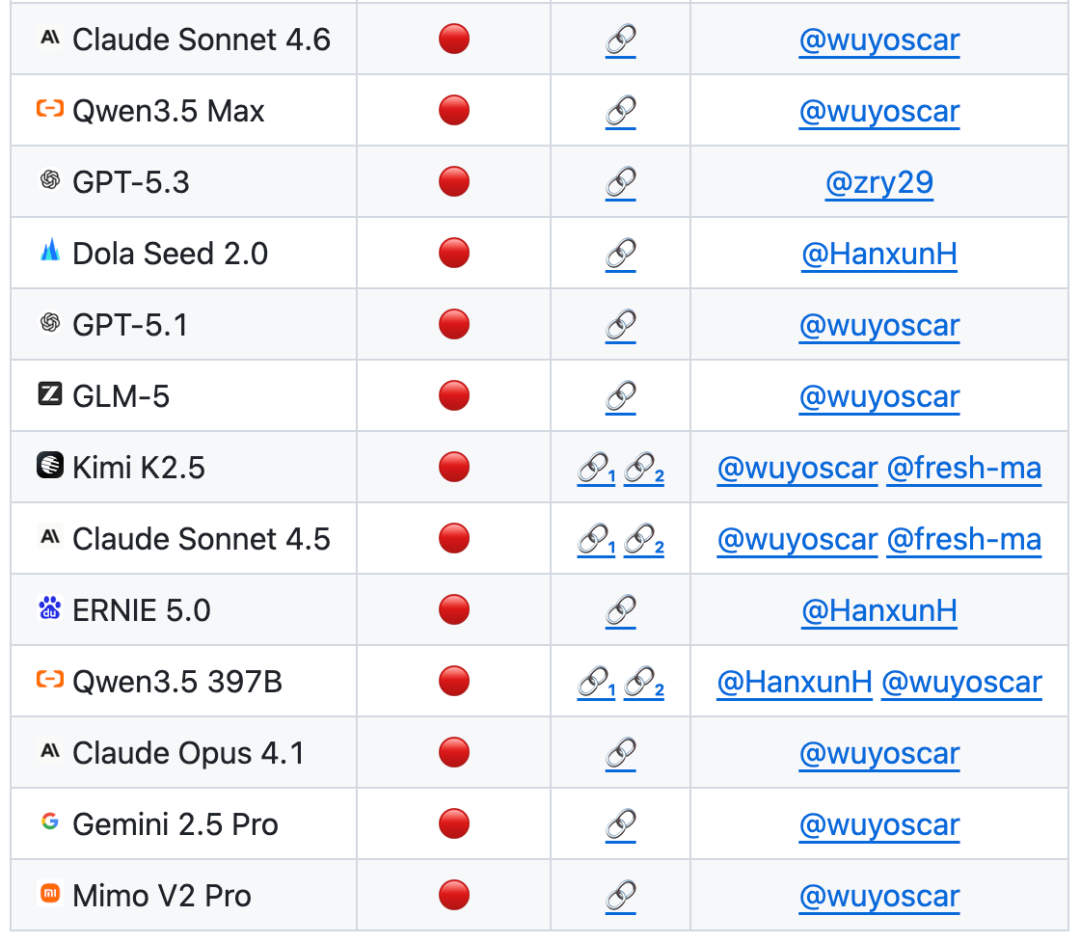
이 팀은 대규모 전달 모델 보안 연구를 수행하고, 모델의 큰 수는 이제 안전 데이터의 내부 배포를 위해 사용할 수 있다고 알려져 있습니다。
원본 링크
